1. はじめに#
1.1 LightPFP とは#
LightPFPとはMatlantisのユーザーが目的の材料についての、軽量の機械学習ポテンシャルを作成するための機能です。
ほとんどの場合、このポテンシャルはPFPよりもパラメータ数が少ないので、シミュレーションを高速化でき、扱えるスケールも大きくなります。
Matlantisのプラットフォーム上でLightPFPを使用することで、データセットの収集・モデルの訓練・推論(原子シミュレーション)を実行することができます。
また量子化学計算よりも高速なPFPの性能を活かし、対象材料の大規模な訓練データセットを容易に生成することができます。
データセットの収集とモデルの訓練は、通常数時間以内に完了することができます。
LightPFPモデルはPFPよりも15〜40倍高速であり、数十万個程度の原子をシミュレーションすることができます。
1.2 サポートする手法#
現在、モーメントテンソルポテンシャル(MTP)のみを提供しております。今後も軽量の機械学習モデルを追加する予定です。
モーメントテンソルポテンシャル (MTP)#
MTPは構造記述子の線形結合によってポテンシャルエネルギーを表現します。
MTPは約100〜1000個の少ないパラメータのみを必要とします。
ペア・角度・高次の相互作用は、テンソル積によって簡便に表現されます。
そのためこのモデルは高い計算効率を持っています。
MTPについては[1]で詳細に説明されています。
ここではMTPモデルからエネルギーを計算する方法と、基底関数の導出方法について要約します。
文中の方程式や図は、元の論文[1]から抽出されたものです。
MTPのエネルギー E は原子ごとのエネルギー (V(n_i)) の総和で表されます。ここで、 (n_i) は構造中の原子iの近傍情報を示します。
(f) は readout 関数と呼ばれ、元の論文では線形関数を用いており、以下のように表されます:
LightPFPでは線形関数に加えて、readout 関数としてニューラルネットワークを使用するオプションも提供しています。詳細は以下のセクションで説明します。
基底関数 (B) の表現方法がMTPの肝で、モーメント関数 (M_{μ,ν}) のテンソル積で表されます。
ここで (z_i)、(z_j) はそれぞれ原子 (i) と (j) の種類を表し、(f_μ) は多項式関数を指します。
また (|r_{ij}|) は原子 (i) と (j) のユークリッド距離であり、⊗はテンソルのクロネッカー積を示します。
上記の式はベクトル (vec{r_{ij}}) のクロネッカー積を (nu) 回とることを意味します。
MTPの複雑さを指定するために、パラメータ levmax, moment_init_cost, moment_mu_cost, moment_nu_cost, n_q が使用されます。
各基底関数のレベルは levmax より小さくなければなりません。
基底のレベルは以下の式で計算することができます。
(n_q) は多項式関数 (f_μ) 内の動径方向の基底関数の数を表します。
基底関数のレベルの計算方法の説明のために、以下の例を[1]から引用しました。
この例では、levmax=8、moment_init_cost=2、moment_mu_cost=4、moment_nu_cost=1と設定した場合、以下の9つの基底関数が妥当であることを示しています。
ここで”·”はベクトルの内積、”:”は2つの行列のフロベニウス積を表します。
基底関数 (B_1) は、μ=0 および v=0 の1つのモーメント関数のみから構成されています。
(B_1) のレベルは、 moment_init_cost + moment_mu_cost * μ + moment_nu_cost * ν = 2 + 4 * 0 + 1 * 0 = 2 と計算されます。
同様に、他の基底関数のレベルは以下のように計算されます。
(B_2) は (M_{1,0}) から構成されています。そのため、レベルは ((2 + 4 times 1 + 1 times 0) = 6) となります。
(B_3) は2つの (M_{0,0}) から構成されています。そのため、レベルは (2 times (2 + 4 times 0 + 1 times 0) = 4) となります。
(B_4) は2つの (M_{0,1}) から構成されています。そのため、レベルは (2 times (2 + 4 times 0 + 1 times 1) = 6) となります。
(B_5) は2つの (M_{0,2}) から構成されています。そのため、レベルは (2 times (2 + 4 times 0 + 1 times 2) = 8) となります。
(B_6) は (M_{0,0}) と (M_{1,0}) から構成されています。そのため、レベルは ((2 + 4 times 0 + 1 times 0) + (2 + 4 times 1 + 1 times 0) = 8) となります。
(B_7) は3つの (M_{0,0}) から構成されています。そのため、レベルは (3 times (2 + 4 times 0 + 1 times 0) = 6) となります。
(B_8) は (M_{0,0}) と2つの (M_{0,1}) から構成されています。そのため、レベルは ((2 + 4 times 0 + 1 times 0) + 2 times (2 + 4 times 0 + 1 times 2) = 8) となります。
(B_9) は4つの (M_{0,0}) から構成されています。そのため、レベルは (4 times (2 + 4 times 0 + 1 times 0) = 8) となります。
一方でこの例では (M_{2,0}) は妥当ではありません。なぜならそのレベルは (2 + 4 times 2 + 1 times 0 = 10) であり、levmax(=8)よりも大きいからです。
また基底関数 (B) はスカラー値である必要がありますが、モーメント関数 (M) は必ずしもそのような制約はありません。
LightPFPパッケージでは、MTPの複雑性のハイパーパラメータとして、levmax、moment_init_cost、moment_mu_cost、moment_nu_costを定義することができます。
直感的には、levmaxが大きく、moment_init_cost・moment_mu_cost・moment_nu_costが小さいほど、MTPは複雑になります。
ただしMTPが複雑になるほど、必要なメモリや計算時間が増加します。
LightPFPで一般的に使用されるハイパーパラメータは、levmax={8, 16}、moment_init_cost={2}、moment_mu_cost={4, 1}、moment_nu_cost={1}です。
前述の通り、MTPに関する過去の研究ではreadout 関数 (f) としては線形結合を用いることが一般的でした。
しかし、私たちはここをニューラルネットワークで置き換えることを試み、ベンチマーク比較を行った結果、
一定の優位性が示されたためニューラルネットワーク readout 関数を用いるオプションを提供することとしました。
ニューラルネットワーク readout 関数は、基底関数の出力を入力として受け取り、ポテンシャルエネル
ギーを出力するニューラルネットワークです。このニューラルネットワークは多層パーセプトロン(MLP)
です。入力ニューロンの数は基底関数の数と同じで、出力ニューロンの数は1です。隠れ層の数と各
隠れ層のニューロン数はユーザーが指定できます。活性化関数には shifted softplus 関数が
使用されます。また、ニューラルネットワークには残差接続が使用されています。
一般的に、ニューラルネットワーク(NN)は複雑なパターンや非線形関係を捉える能力に優れているため、
ほとんどの場合で線形結合よりも精度は高くなります。しかし、線形結合にはより単純で解釈しやすいという
利点もあります。入力特徴量と目標変数の関係が線形であると予想される場合や、訓練データの量が限られている
場合には、線形結合を選ぶべきでしょう。
1.3 コンポーネント#
(a) light-pfp-data パッケージ#
Matlantis上で以下のコマンドを実行することでインストールできます。
pip install light-pfp-data
このパッケージを用いることで、目的の材料についての訓練データセットを収集することができます。
注意: このパッケージは収束性のバグ修正が含まれたscipyバージョンに依存しているため、Python 3.9のみと互換性があり、Python 3.8以前のバージョンはサポートしていません。
(b) 訓練#
訓練のための追加パッケージはありません。
ユーザーは submit-light-pfp-training というCLIツールを用いて、Light PFPの教師データを登録することができます。
このツールはMatlantis ノートブック上に提供されています。
訓練ジョブは、ノートブックとは別のコンピューティングリソース上で実行されます。
訓練後、Light PFPが作成したモデルは「モデルライブラリ」というクラウド環境に保存されます。
詳細については 3. LightPFPモデルの訓練 の章を参照してください
(c) light-pfp-client パッケージ#
Matlantis上で以下のコマンドを実行することでインストールできます。
pip install light-pfp-client
このパッケージを用いることで、作成済みのLight PFPモデルをcalculatorクラスを通して呼び出し、原子シミュレーションを実行できます。
注意: 現在、light-pfp-clientではPython 3.9のみをサポートしています。Python 3.8でも動作する可能性はありますが、私たちのすべての例とテストはPython 3.9で実行されています。
(d) light-pfp-evaluate パッケージ#
Matlantis上で以下のコマンドを実行することでインストールできます。
pip install light-pfp-evaluate
このパッケージを用いることで、LightPFPモデルの性能を評価することができます。
具体的には、与えられた構造に対して状態方程式やフォノン分散などの基本的な物性値を計算し、PFPの結果と比較することでモデルを評価することができます。
また、このパッケージではモデルを評価するためのCLIも提供されています。
より詳細な説明については、 5. LightPFPモデルの評価 の章を参照してください。
2. 訓練用データの生成#
2.1 CLI ツール#
dataset-generation CLIツールはlight-pfp-dataパッケージに含まれています。
パッケージのインストール後、このツールを使用してさまざまな訓練構造の収集を自動化することができます。
ツールを利用するために、いくつかの初期構造と、JSON形式の制御ファイルを準備する必要があります。
制御ファイルにはデータ生成プロセスを制御する引数が指定されています。
これらの引数について以下で説明します。
以下の方法でCLIツールを使用できます。
PFP_DEFAULT_PRIORITY=1 dataset-generation -c your_control_file.json -l info -p true -j 2
PFPトークン消費を抑えるために、データ生成では上記のように PFP_DEFAULT_PRIORITY を最低値に設定することを推奨します。
dataset-generation コマンドの引数は以下の通りです。
-
-c,--config(Required): JSON形式の制御ファイルのパス。 -
-l,--log-level(Optional): ログレベル。デフォルトは info です。 -
-p,--progress-bar(Optional): true か false を設定します。 true が設定された場合、全てのタスクに対してプログレスバーを表示します。デフォルトは true です。 -
-j,--num-threads(Optional): 並列実行のためのスレッド数(利用可能なCPUコア数を大きく上回る値を指定した場合、パフォーマンスが低下する可能性があります)。デフォルトは8です。
PFPで計算された訓練構造(格子・元素・原子位置を含む)とそれらのポテンシャルエネルギー・力・応力を含むHDF5ファイルが出力されます。
注意:このツールを用いたデータ生成は同期的で、かつPFPによる並列計算を行うために多くのCPUリソースを使用します。
処理が予期せず停止することを防ぐため、バックグラウンドでの実行を推奨します。
例としてバックグラウンドモードのノートブックやtmux、バックグラウンドでのbashスクリプトなどの方法があります。
またMatlantisノートブック環境内のCPUリソースへの負荷を下げるため、この処理の実行中は同環境で他の処理を実行しないことを推奨します。
2.2 データ生成の制御ファイル#
(a) 簡単なJSONファイルの例#
dataset-generation CLIツールの使用の際、訓練データの生成に関するパラメータを指定するために、JSON形式の制御ファイルが必要です。
以下に、簡単な制御ファイルの例を示します:
{
"version": 2,
"initial_structure": ["test1.cif", "test2.cif"],
"dataset_path": "test.h5",
"pfp_model_version": "v5.0.0",
"pfp_calc_mode": "crystal_u0",
"initial_opt": true,
"md": [
{
"sampling_temp": [500.0],
"sampling_steps": [10000],
"sampling_interval": [100],
"supercell": [3, 3, 3],
"ensemble": "npt"
},
{
"sampling_temp": [1500.0],
"sampling_steps": [5000],
"sampling_interval": [100],
"supercell": [4, 4, 4],
"ensemble": "nvt"
}
]
}
設定ミス防止のため、制御ファイル内の値には型チェックが適用されます。想定とは異なる型が設定されている場合、ジョブの開始時にエラーが表示されます。
(b) 引数#
-
version(int, Optional, default=1):-
制御ファイルのスキーマのバージョンです。互換性を保つ必要がある場合以外は2を指定してください。
αリリース時と互換性のあるバージョン1のスキーマを利用することも可能ですが、非推奨です。
バージョン1は将来のリリースで削除される予定です。
-
initial_structure(List[str], Required):-
初期構造のファイルパス(複数可)。ASE.ioのサポートするファイル形式を使用可能です。
-
dataset_path(str, Required, Required):-
H5形式のデータセットファイルパス
-
pfp_model_version(str, Required):-
PFPのバージョン。デフォルトは”v6.0.0”です。
-
pfp_calc_mode(str, Required):-
PFPの計算モード。デフォルトは”crystal_u0”です。
-
initial_opt(bool, Required):-
訓練データの構造を生成する前に、初期構造をPFPで最適化します。デフォルトはtrueです。
ユーザーは”initial_structure” と “dataset_path” を指定する必要があります。
(c) セクション#
共通の引数の後で、”initial_structure” から訓練構造を生成する方法を指定することができます。
上記の例では、”md” リストで指定されているように、2つの分子動力学(MD)タスクが実行されます。
最初のタスクは、3x3x3のスーパーセルを使用して、500Kで10,000ステップのNPT MDを実行します。
2番目のタスクは、4x4x4のスーパーセルを使用して、1500Kで5,000ステップのNVT MDを実行します。
以下のように、訓練構造を生成するためのいくつかの方法が提供されています。
-
MD
-
圧縮
-
変形
-
変位
-
空孔
-
表面
-
置換
また、制御ファイル内で複数の訓練構造の生成手法(例えばMDと圧縮など)を指定することができます。
複数の手法が指定された場合、それらは initial_structure で指定された初期構造( initial_opt が指定された場合はそれが最適化された構造)から独立して生成されます。
なお、LightPFPのExampleの「Tutorial」ノートブックでは複数の生成手法を指定して訓練データを生成しています。
そちらも併せて参照してください。
以下のセクションでは各手法について説明します。
2.3 手法#
訓練データセットは、初期構造にさまざまな変更を加えることで生成されます。
MDシミュレーションは訓練構造を収集するための最も基本的で強力な方法ですが、単純なMDシミュレーションでは得られない構造もあります。
訓練データセットの多様性を確保するために、MD以外の方法も提供しております。
訓練構造の生成方法について以下で説明します。
(a) MDシミュレーションによる構造のサンプリング#
MDシミュレーションは、訓練構造をサンプリングするための強力なツールです。
温度を変化させることで、異なる乱雑さを持つ訓練構造を得ることができます。
高い温度ではより無秩序な構造を得ることができ、これらはLightPFPモデルの訓練をよりロバストにするために役立ちます。
データセット生成ツールでは、指定された条件(温度、圧力など)で指定されたステップ数のMDシミュレーションを行うことができます。
ユーザーはNPT(粒子数、圧力、温度が一定)またはNVT(粒子数、体積、温度が一定)アンサンブルのどちらかを選択できます。
類似した構造が過剰に収集されるのを避けるため、Nステップごと(100ステップなど)にスナップショットが取られます。
ユーザーは、”md”をtrueに設定することでMDサンプリングを有効にすることができます。
制御ファイルの”md”引数は、個々のMDシミュレーションを指定するパラメータの辞書のリストです。
以下は、全ての引数とそれらのデフォルト値が示された制御ファイルの例です。
制御ファイル:#
{
"version": 2,
"initial_structure": ["test1.cif", "test2.cif"],
"dataset_path": "test.h5",
"pfp_model_version": "v5.0.0",
"pfp_calc_mode": "crystal_u0",
"initial_opt": true,
"md": [
{
"sampling_temp": [500.0],
"sampling_steps": [10000],
"sampling_interval": [100],
"sampling_pressure": [1],
"timestep": 1.0,
"supercell": [3, 3, 3],
"ensemble": "npt"
},
{
"sampling_temp": [1500.0],
"sampling_steps": [5000],
"sampling_interval": [100],
"sampling_pressure": [1],
"timestep": 1.0,
"supercell": [4, 4, 4],
"ensemble": "nvt"
}
]
}
MD の引数:#
-
supercell(Tuple[int, int, int], Optional, default=[3, 3, 3]):-
初期構造をスーパーセルに拡張します。
-
sampling_temp(List[float], Optional, default=[500.0]):-
MDシミュレーションの温度(K)です。
-
sampling_steps(List[int], Optional, default=[1000]):-
各温度でのMDのステップ数です。リスト長はsampling_tempと一致する必要があります。
-
sampling_interval(List[int], Optional, default=[100]):-
各温度で指定されたステップごとに訓練構造を収集します。リスト長はsampling_tempと一致する必要があります。
-
sampling_pressure(List[float], Optional, default=[1.0]):-
MDシミュレーションの圧力(bar単位)です。リスト長はsampling_tempと一致する必要があります。
-
timestep(float, Optional, default=1.0):-
全てのMDタスクにおける時間ステップ(fs)です。
-
ensemble(str, Optional, default=”npt”):-
MDのアンサンブルです。”nvt”と”npt”がサポートされています。
mdのリストの各要素は、それぞれ独立に扱われます。同じ初期構造から計算が実行され、リスト内の他の要素による計算結果は引き継がれません。
(b) 一様な伸縮#

与えられた初期構造の格子を均一に圧縮または引き伸ばすことで、一連の訓練構造が生成されます。
これらの構造により、LightPFPモデルは体積とポテンシャルエネルギーの関係を学ぶことができます。
a、b、c軸に沿った格子長の変化率は同じであり、任意の2軸間の角度は変化しません。
原子の分率座標は固定されます。
より堅牢な訓練データセットを得るために、圧縮または引き伸ばされた構造を作成した後に、構造最適化とMDシミュレーションを行って追加の訓練構造を収集することもできます。
なお、構造最適化とMDシミュレーションでは格子は固定されています。
以下は、全ての可能な引数とそれらのデフォルト値が示された制御ファイルの例です。
制御ファイル:#
{
"version": 2,
"initial_structure": ["test1.cif", "test2.cif"],
"dataset_path": "test.h5",
"pfp_model_version": "v5.0.0",
"pfp_calc_mode": "crystal_u0",
"initial_opt": true,
"compress": [
{
"supercell": [1, 1, 1],
"min_scale": 0.95,
"max_scale": 1.05,
"interval": 0.01,
"opt": false,
"md": false,
"sampling_temp": [500.0],
"sampling_steps": [1000],
"sampling_interval": [100],
"timestep": 1.0
}
]
}
伸縮の引数:#
-
supercell(Tuple[int, int, int], Optional, default=[1, 1, 1]):-
入力構造をスーパーセルに拡張します。
-
min_scale(float, Optional, default=0.95):-
セルの長さを最小でこの比率に圧縮します(0 < min_scale < max_scale)。
-
max_scale(float, Optional, default=1.05):-
セルの長さを最大でこの比率まで引き伸ばします(min_scale以上)。
-
interval(float, Optional, default=0.01):-
min_scaleとmax_scale間で、この間隔で構造を生成します(0 < interval <= (max_scale-min_scale))。
-
opt(bool, Optional, default=False):-
Trueの場合、圧縮や引き伸ばし後に構造を最適化します。
-
md(bool, Optional, default=False):-
Trueの場合、追加の構造を収集するためにMDシミュレーションを実行します。
-
sampling_temp(List[float], Optional, default=[500.0]):-
MDシミュレーションの温度(K)です。
-
sampling_steps(List[int], Optional, default=[1000]):-
各温度で実行するMDのステップ数です。リスト長はsampling_tempと一致する必要があります。
-
sampling_interval(List[int], Optional, default=[100]):-
各温度ごとに、指定されたステップ数ごとに訓練構造を収集します。リスト長はsampling_tempと一致する必要があります。
-
timestep(List[float], Optional, default=1.0):-
各温度ごとの時間ステップ(fs単位)です。timestepのリスト長はsampling_tempと一致する必要があります。
compressのリストの各要素は、それぞれ独立に扱われます。同じ初期構造から計算が実行され、リスト内の他の要素による計算結果は引き継がれません。
(c) 歪み#

初期構造に対して垂直ひずみとせん断ひずみを適用して一連の訓練構造が作成されます。
これらの構造により、LightPFPモデルは対象物質の弾性挙動を学ぶことができます。
6種類のひずみ(xx、yy、zz、yx、xz、xy)のうちの1つが3D格子に適用されます。
この場合、格子の長さと軸の角度の両方が変化する可能性があります。
変形後には、原子の位置も最適化することができます。
以下は、全ての可能な引数とそれらのデフォルト値が示された制御ファイルの例です。
制御ファイル:#
{
"version": 2,
"initial_structure": ["test1.cif", "test2.cif"],
"dataset_path": "test.h5",
"pfp_model_version": "v5.0.0",
"pfp_calc_mode": "crystal_u0",
"initial_opt": true,
"deformed": [
{
"supercell": [2, 2, 2],
"min_strain": -0.01,
"max_strain": 0.01,
"interval": 0.005,
"opt": false
}
]
}
歪みの引数:#
-
supercell(Tuple[int, int, int], Optional, default=[2, 2, 2]):-
入力構造をスーパーセルに拡大します。
-
min_strain(float, Optional, default=-0.01):-
格子に適用される最小ひずみです。
-
max_strain(float, Optional, default=0.01):-
格子に適用される最大ひずみです。
-
interval(float, Optional, default=0.005):-
最小ひずみと最大ひずみの間で、この間隔で構造を生成します。
-
opt(bool, Optional, default=False):-
Trueの場合、変形後に構造を最適化します。
deformedのリストの各要素は、それぞれ独立に扱われます。同じ初期構造から計算が実行され、リスト内の他の要素による計算結果は引き継がれません。
(d) 原子位置の変位#

x、y、またはz方向に指定された距離だけ1つの原子を変位させることで訓練構造を作成します。
これらの構造は、LightPFPモデルが平衡位置周りの力定数やフォノン特性を学ぶのに役立つと考えられます。
制御ファイル:#
{
"version": 2,
"initial_structure": ["test1.cif", "test2.cif"],
"dataset_path": "test.h5",
"pfp_model_version": "v5.0.0",
"pfp_calc_mode": "crystal_u0",
"initial_opt": true,
"displaced": [
{
"supercell": [3, 3, 3],
"delta": 0.1,
"n_sample": null
}
]
}
原子位置変位の引数:#
-
supercell(Tuple[int, int, int], Optional, default=[3, 3, 3]):-
入力構造をスーパーセルに拡大します。
-
delta(float, Optional, default=0.1):-
オングストローム単位の変位距離です。
-
n_sample(int, Optional, default=None): :-
生成する訓練構造の数です。指定しない場合は、num_atoms*3となります。
displacedのリストの各要素は、それぞれ独立に扱われます。同じ初期構造から計算が実行され、リスト内の他の要素による計算結果は引き継がれません。
(e) 空孔#

初期構造からランダムに1つまたは複数の原子を取り除いて欠陥のある構造を作成します。
これらの構造により、LightPFPモデルが対象材料における欠陥の効果を学習することができます。
欠陥構造に対して、構造最適化やMDシミュレーションを行うことで追加の訓練構造を収集することもできます。
構造最適化とMDシミュレーションでは、セルの形状は固定されています。
制御ファイル:#
{
"version": 2,
"initial_structure": ["test1.cif", "test2.cif"],
"dataset_path": "test.h5",
"pfp_model_version": "v5.0.0",
"pfp_calc_mode": "crystal_u0",
"initial_opt": true,
"vacancy": [
{
"supercell": [3, 3, 3],
"n_vacancy": 1,
"n_sample": 10,
"opt": true,
"md": false,
"sampling_temp": [500.0],
"sampling_steps": [1000],
"sampling_interval": [100],
"timestep": 1.0
}
]
}
空孔の引数:#
-
supercell(Tuple[int, int, int], Optional, default=[3, 3, 3]):-
入力構造をスーパーセルに展開します。
-
n_vacancy(int, Optional, default=1):-
1つの構造に作成する欠陥の数です。
-
n_sample(int, Optional, default=10):-
生成される欠陥構造の数です。
-
opt(bool, Optional, default=True):-
Trueの場合、欠陥構造を最適化します。
-
md(bool, Optional, default=False):-
Trueの場合、より多くの構造を収集するためにMDシミュレーションを実行します。
-
sampling_temp(List[float], Optional, default=[500.0]):-
MDシミュレーションの温度(K)です。
-
sampling_steps(List[int], Optional, default=[1000]):-
各sampling_tempで実行するMDステップ数です。リストのサイズはsampling_tempのサイズと一致する必要があります。
-
sampling_interval(List[int], Optional, default=[100]):-
各sampling_tempごとに、このステップ数ごとに訓練構造を収集します。リストのサイズはsampling_tempのサイズと一致する必要があります。
-
timestep(float, Optional, default=1.0):-
すべてのMDタスクの時間ステップ(fs)です。
vacancyのリストの各要素は、それぞれ独立に扱われます。同じ初期構造から計算が実行され、リスト内の他の要素による計算結果は引き継がれません。
(f) 表面構造#

初期構造をあるミラー指数に従って切断することで、一連の表面構造を作成することができます。
これらの構造により、LightPFPモデルは表面特性を学習することができます。
通常は低いミラー指数((0 0 1)など)から始め、ユーザー指定の上限まで指数を徐々に増加させます。
構造の対称性を考慮し、異なるミラー指数で同じ表面構造を収集しないようにします。
表面構造で構造最適化とMDシミュレーションを実行することで、追加の訓練用構造を収集することができます。
構造最適化とMDシミュレーションの間、セルの形状は固定されます。
制御ファイル:#
{
"version": 2,
"initial_structure": ["test1.cif", "test2.cif"],
"dataset_path": "test.h5",
"pfp_model_version": "v5.0.0",
"pfp_calc_mode": "crystal_u0",
"initial_opt": true,
"surface": [
{
"supercell": [1, 1, 1],
"max_index": 2,
"min_slab_size": 10.0,
"min_vacuum_size": 10.0,
"opt": true,
"md": false,
"sampling_temp": [500.0],
"sampling_steps": [1000],
"sampling_interval": [100],
"timestep": 1.0
}
]
}
表面構造の引数:#
-
supercell(Tuple[int, int, int], Optional, default=[1, 1, 1]):-
入力構造をスーパーセルに展開します。
-
max_index(int, Optional, default=2):-
最大のミラー指数です。
-
min_slab_size(float, Optional, default=10.0):-
スラブの厚さ(オングストローム)です。
-
min_vacuum_size(float, Optional, default=10.0):-
真空層の厚さ(オングストローム)です。
-
opt(bool, Optional, default=True):-
Trueの場合、表面構造を最適化します。
-
md(bool, Optional, default=False):-
Trueの場合、より多くの構造を収集するためにMDシミュレーションを実行します。
-
sampling_temp(List[float], Optional, default=[500.0]):-
MDシミュレーションの温度(K)です。
-
sampling_steps(List[int], Optional, default=[1000]):-
各sampling_tempで実行するMDステップ数です。sampling_stepsのリスト長はsampling_tempのリスト長と一致する必要があります。
-
sampling_interval(List[int], Optional, default=[100]):-
各sampling_tempで、このステップ数ごとに訓練構造を収集します。
sampling_intervalのリスト長はsampling_tempのリスト長と一致する必要があります。
-
timestep(float, Optional, default=1.0):-
すべてのMDタスクの時間ステップ(fs)です。
surfaceのリストの各要素は、それぞれ独立に扱われます。同じ初期構造から計算が実行され、リスト内の他の要素による計算結果は引き継がれません。
(g) 元素の置換による構造の生成#

初期構造の元素を置換することで訓練構造を生成します。
この手法は高エントロピー合金(HEA)などの特定の材料に有用です。
初期構造について、指定した元素が指定した確率で置換されます。
元素の置換後に構造最適化とMDシミュレーションを行うことで、追加の訓練構造を収集することもできます。
構造最適化とMDシミュレーションの間、セルの形状は固定されます。
制御ファイル:#
{
"version": 2,
"initial_structure": ["test1.cif", "test2.cif"],
"dataset_path": "test.h5",
"pfp_model_version": "v5.0.0",
"pfp_calc_mode": "crystal_u0",
"initial_opt": true,
"substitution": [
{
"n_sample": 10,
"elements": [1],
"possibility": [0.01],
"supercell": [3, 3, 3],
"opt": true,
"md": false,
"sampling_temp": [500.0],
"sampling_steps": [1000],
"sampling_interval": [100],
"timestep": 1.0
}
]
}
元素の置換の引数:#
-
n_sample(int, Optional, default=10):-
生成する構造の数です。
-
elements(List[int], Optional, default=[1]):-
置換する元素の原子番号です。elementsのリスト長はpossibilityと一致する必要があります。
-
possibility(List[float], Optional, default=[0.01]):-
各元素を置換する確率です。リストのサイズはelementsと一致する必要があります。
-
supercell(Tuple[int, int, int], Optional, default=[3, 3, 3]):-
入力構造をスーパーセルに拡張します。
-
opt(bool, Optional, default=True):-
Trueの場合、置換された構造を最適化します。
-
md(bool, Optional, default=False):-
Trueの場合、追加の構造を収集するためにMDシミュレーションを実行します。
-
sampling_temp(List[float], Optional, default=[500.0]):-
MDシミュレーションの温度(K)です。
-
sampling_steps(List[int], Optional, default=[1000]):-
各sampling_tempで実行するMDステップ数です。リストのサイズはsampling_tempと一致する必要があります。
-
sampling_interval(List[int], Optional, default=[100]):-
各sampling_tempで、このステップ数ごとに訓練構造を収集します。リストのサイズはsampling_tempと一致する必要があります。
-
timestep(float, Optional, default=1.0):-
すべてのMDタスクの時間ステップ(fs)です。
substitutionのリストの各要素は、それぞれ独立に扱われます。同じ初期構造から計算が実行され、リスト内の他の要素による計算結果は引き継がれません。
2.4 ASEトラジェクトリからのカスタムデータセット#
ユーザーは traj-to-dataset CLIツールを用いて、事前に作成したASE MDトラジェクトリをLightPFPデータセットに変換することもできます。
なお、現在はPFPで作成したトラジェクトリのみがサポートされています。
トラジェクトリがPFPによって生成された場合、 –model-version と –calc-mode オプションを通じてPFPモデルバージョンと計算モードを提供することを推奨します。
これらの情報は、データセット検証や事前学習モデルの選択などの後続の分析で使用されます。
traj-to-dataset --traj user_pfp_traj.traj --dataset user_custom.h5 --calc-mode crystal_u0 --model-version v5.0.0 --start 0 --end 10000
ただし、トラジェクトリがPFPではなくDFTなど他のソースから生成された場合でも、LightPFPデータセットに変換することができます。
この場合、ユーザーは –calc-mode と –model-version オプションを省略することができます。
traj-to-dataset --traj user_dft_traj.traj --dataset user_custom.h5 --start 0 --end 10000
ASEトラジェクトリ形式に加えて、CLIはVASP OUTCARやQuantum ESPRESSOの出力ファイルなど、様々なDFTソフトウェアの出力ファイルを直接処理することができます。
ファイル形式は –format オプションで指定する必要があります。
例えば、Quantum ESPRESSO出力ファイルには espresso-out を、VASP OUTCARファイルには vasp-out を使用します。
traj-to-dataset --traj qe_md.out --dataset user_custom.h5 --format espresso-out
traj_to_datasetの引数は以下の通りです。
-
--traj(Required): 入力とするASEトラジェクトリ。 -
--dataset(Required): H5DF形式の出力データセットファイル。 -
--calc-mode(Optional): PFP計算モード。この情報は2つの目的で使用されます:(1) データの一貫性を確保するためのデータセット検証、および (2) 適切な事前学習モデルの選択。トラジェクトリがPFPで生成された場合、使用されたモードと一致させることを推奨。デフォルト: “”(空文字列)。 -
--model-version(Optional): PFPモデルバージョン。この情報はデータの一貫性を確保するためのデータセット検証に使用されます。トラジェクトリがPFPで生成された場合、使用されたバージョンと一致させることを推奨。デフォルト: “”(空文字列)。 -
--start(Optional): トラジェクトリの開始スライス。デフォルト:0。 -
--end(Optional): トラジェクトリの終了スライス。デフォルト:None(トラジェクトリの最後)。 -
--step(OPtional): トラジェクトリをスライスするステップ。デフォルト:1。 -
--format(Optional): 入力ファイルの形式を指定します。デフォルト:”traj”。CLIはASE IOを使用して入力ファイルの処理と解析を行うため、サポートされているファイル形式については ASE IOのドキュメント を参照してください。
2.5 データセットの検証とスクリーニング#
一部の訓練構造は、LightPFPモデルの精度と堅牢性に悪影響を及ぼす可能性があります。
非常に高いポテンシャルエネルギーや大きな力を持つ構造がそのような構造の例です。
これらの構造はデータセット生成のためのさまざまなシミュレーションで収集されるため、非常に現実的でない構成(2つの原子が非常に近接している構成など)を含みます。
これらの破壊的なデータを検出するためのCLIツールを提供しています。–delete_invalid_keysオプションを指定することで、これらの破壊的なデータを取り除くすることもできます。
また–dataset d1.h5 –dataset d2.h5のように、–datasetオプションに複数のデータセットが指定されている場合、CLIはこれらのデータセット間のmodel_versionとcalc_modeの一貫性をチェックします。
validate-dataset --datasets path_to_dataset.h5 --max-energy -3.0 --max-forces 30.0
validate-datasetの引数は以下の通りです。
-
--datasets,-d(Required): チェックするデータセットのパス。 -
--max-energy(Optional): 原子あたりのポテンシャルエネルギーがこの値より大きい構造がデータセットに含まれている場合、警告メッセージを表示します。デフォルトは0です。 -
--max-forces(Optional): 力がこの値より大きい構造がデータセットに含まれている場合、警告メッセージを表示します。デフォルトは20です。 -
--delete-invalid-keys(Optional): true にセットされた場合、非常に高いポテンシャルエネルギーや大きな力を持つ構造に対応するキーを削除します。デフォルトは false です。 -
--inline-delete(Optional): true がセットされた場合、バックアップなしでデータセットの無効なキーを削除します。このオプションは、–delete_invalid_keysオプションと一緒に使用する場合にのみ有効です。デフォルトは false です。
3. LightPFPモデルの訓練#
3.1 はじめに#
訓練ジョブの目的は、与えられた材料においてエネルギー・力・応力を正確に予測できるLightPFPモデルを生成することです。
この目的は、LightPFPモデルによる予測と訓練データセットの対応する値との差を最小化することによって達成されます。
訓練ジョブを開始するには、以下を指定する必要があります。
-
訓練ジョブパラメータを指定するJSON形式の制御ファイル
-
事前に生成された訓練データを含む、HDF5データセットファイル(複数可)。エネルギーおよび力の情報が必須です。圧力の情報は省略できます。
以下は制御ファイルの例です。
{
"common_config": {
"total_epoch": 200
},
"mtp_config": {
"pretrained_model": "ALL_ELEMENTS_SMALL_6"
}
}
-
total_epoch は訓練エポックの総数です。
-
pretrained_model は事前学習済みモデルを使用して訓練を開始するための設定です。
制御ファイルとデータセットファイルが準備できたら、以下のコマンドを使用してジョブを送信します。
デフォルトでは送信前にデータセットの検証を行うため、事前に light-pfp-data パッケージをインストールしておく必要があります。
submit-light-pfp-training -c path_to_control_file.json -d path_to_dataset_file1.h5 path_to_dataset_file2.h5 --model-name descriptive_model_name
submit-light-pfp-training の引数は以下の通りです。
-
--dataset-path,-d(Required): データセットの相対パス。 -d dataset1 -d dataset2 または -d dataset1 dataset2 のように指定します。 -d *.h5 を使用して複数のファイルに展開することもできます。 -
--train-config-path,-c(Required): 訓練ジョブの制御ファイルのパス。 -
--model-name(Optional): 訓練済みモデルの名前。指定されていない場合はランダムに生成されます。 -
--skip-validation(Optional): データセットの検証をスキップします。デフォルトは false です。
このコマンドはサーバーに入力ファイルをアップロードするため、生成されたデータセットのサイズによっては時間がかかる場合があります。
また、合計で1GBを超えるデータセットを用いた学習はサポートしておりません。
ジョブが正常に送信された場合、以下のメッセージが表示されます。
2024/01/15 12:00:06 compressing file path_to_dataset_file1.h5...
2024/01/15 12:00:06 compressing file path_to_dataset_file2.h5...
2024/01/15 12:00:06 Completed creating the input zip file: /tmp/light-pfp-input-2888282202.zip
2024/01/15 12:00:07 Complete! Training job ID: examplesv1alni3s will be started.
注:ここで表示される訓練ジョブIDを控えておいてください。このIDは、次のセクションで説明されるモデルライブラリ内のmodel_idです。
訓練ジョブが完了した後、ユーザーはこのIDを使用してLightPFPモデルをロードし、原子シミュレーションに使用することができます。
制御ファイルのパラメータ#
制御ファイルのパラメータは以下の通りです。
-
total_epoch(int, Optional, default=400):-
訓練全体のプロセスのエポック数
-
pretrained_model(str):-
事前学習済みモデルを指定します。サポートされている事前学習済みモデルは、 (a) 事前学習済みモデル のセクションに記載しています。
例の制御ファイルの説明#
上記の制御ファイルを用いて、訓練ジョブがどのように機能するかを説明します。
-
訓練ジョブは、指定された事前学習済みモデル(この例では “ALL_ELEMENTS_SMALL_6”)を用いて初期化されます。
-
- 訓練全体のプロセスは、異なる目的を持つ3つのステージに分かれています。
-
-
第1ステージでは、Light PFPモデルによって計算された力と、データセットのターゲット原子力値との差を最小限に抑えることに注力します。
-
第2ステージでは、ポテンシャルエネルギーと応力値に適合するように注力します。
-
第3ステージでは、エネルギー・力・応力に割り当てられた重みをバランスよく調整し、モデルがこれら3つの属性全てについてうまく機能するようにします。
-
-
各ステージでのエポック数は、total_epochパラメータによって決定されます。具体的には、第1ステージはtotal_epoch/4エポック、第2ステージはtotal_epoch/2エポック、第3ステージは残りのtotal_epoch/4エポックを実行します。
-
訓練が完了すると、訓練済みのLight PFPモデルがモデルライブラリにアップロードされます。ユーザーは、提供された訓練ジョブID(モデルIDとしても用いられます)を使用して、訓練されたモデルをロードして原子シミュレーションに使用できます。
注:特定の事前学習済みモデルは、”ORGANIC”などの一部の元素のみをサポートしています。サポート外の元素でモデルを訓練すると、エラーが発生します。
3.2 モデル訓練の詳細#
訓練ジョブは、LightPFPモデルとPFPモデルのエネルギー/力/応力の差を最小化するようにLightPFPモデルのパラメータを調整します。
データセットはランダムに訓練(90%)とテスト(10%)に分割されます。
訓練セットはモデルパラメータを適合させるために使用され、テストセットはモデルの精度を示すために使用されます。
パラメータの最適化にはPyTorchが使用されます。
(a) 事前学習済みモデル#
多様な構造からなる大規模なデータセットを使用して訓練された、いくつかの事前学習済みモデルを提供しています。
多くの場合、事前学習済みモデルをファインチューニングすることで、比較的短時間で目標材料に対して高精度なMTPモデルを獲得することができます。
事前学習済みモデルからファインチューニングされたモデルは、特にデータセットが小さく訓練時間が短い場合には、常にスクラッチで訓練されたモデルよりも優れた性能を発揮することが検証されました。
詳細については、 付録2: 事前学習済みモデルのベンチマーク結果 を参照してください。
目標とする構造に対して適切に事前学習済みモデルを選択することが重要です。
事前学習済みモデルとその詳細を以下の表に示します。
|
Name |
levmax |
moment_mu_cost |
rc |
readout |
Supported elements |
|---|---|---|---|---|---|
|
ORGANIC_SMALL |
8 |
1 |
6.0 |
linear function |
H, C, N, O, F, Si, P, S, Cl, Br, I |
|
ORGANIC_LARGE |
16 |
4 |
6.0 |
linear function |
H, C, N, O, F, Si, P, S, Cl, Br, I |
|
ORGANIC_SMALL_NN |
8 |
1 |
6.0 |
NN, 2 layers, 32 hidden nodes |
H, C, N, O, F, Si, P, S, Cl, Br, I |
|
ORGANIC_LARGE_NN |
16 |
4 |
6.0 |
NN, 2 layers, 128 hidden nodes |
H, C, N, O, F, Si, P, S, Cl, Br, I |
|
ALL_ELEMENTS_SMALL_5 |
8 |
1 |
5.0 |
linear function |
All elements supported by PFP v6.0 |
|
ALL_ELEMENTS_SMALL_6 |
8 |
1 |
6.0 |
linear function |
All elements supported by PFP v6.0 |
|
ALL_ELEMENTS_SMALL_7 |
8 |
1 |
7.0 |
linear function |
All elements supported by PFP v6.0 |
|
ALL_ELEMENTS_SMALL_NN_6 |
8 |
1 |
6.0 |
NN, 2 layers, 16 hidden nodes |
All elements supported by PFP v6.0 |
|
ALL_ELEMENTS_LARGE_5 |
16 |
4 |
5.0 |
linear function |
All elements supported by PFP v6.0 |
|
ALL_ELEMENTS_LARGE_6 |
16 |
4 |
6.0 |
linear function |
All elements supported by PFP v6.0 |
|
ALL_ELEMENTS_LARGE_7 |
16 |
4 |
7.0 |
linear function |
All elements supported by PFP v6.0 |
|
ALL_ELEMENTS_LARGE_NN_6 |
16 |
4 |
6.0 |
NN, 2 layers, 16 hidden nodes |
All elements supported by PFP v6.0 |
それぞれの事前学習済みモデルは、特定の元素のセットでトレーニングされています。もし目的の材料に事前学習済みモデル
に含まれていない元素が存在する場合、その未サポートの元素にはランダムな初期パラメータが割り当てられます。
有機分子には、”ORGANIC”事前学習済みモデルを使用することをお勧めします。
“ORGANIC”事前学習済みモデルの訓練データは、PFPのcalc_mode=CRYSTAL_U0_PLUS_D3でラベル付けされた有機分子です。
なお、”ORGANIC”事前学習済みモデルの未サポート元素の中で、”ALL_ELEMENTS_SMALL_6”ではサポートされている元素は”ALL_ELEMENTS_SMALL_6”のパラメータで初期化されます。
それ以外の”ORGANIC”事前学習済みモデルの未サポート元素はランダムなパラメータで初期化されます。
結晶などの他の構造については、”ALL_ELEMENTS_
“ALL_ELEMENTS_
計算条件についての詳細は、「PFPについて」を参照してください。
LARGEベースのMTPモデルはSMALLベースのMTPモデルよりも遅いため、まずSMALLを試し、その精度に満足できない場合はLARGEを試してください。
事前学習済みモデルは、計算条件が異なる場合でも、ファインチューニングを行うことで訓練データに適用可能です。
例えば”ALL_ELEMENTS_
これにより、事前学習済みモデルの計算条件とは異なる計算条件の計算結果を、正確に再現することができることが検証されました。
(b) 損失関数#
損失関数は、エネルギー損失・力損失・応力損失の3つの部分からなります。ユーザーは各要素の係数を指定できます。
エネルギー損失は次のように表されます。
ここで、 (N) はミニバッチ内の構造の数、
(f) は損失関数(MSEなど)、
(A_i) は構造 (i) 内の原子数、
(E_{PFP}) および (E_{LightPFP}) はそれぞれPFPおよびLightPFPによって計算された構造 (i) のポテンシャルエネルギーを表します。
力損失は次のように表されます。
ここで、(N) はミニバッチ内の構造の数、
(M_i) は構造 (i) 内の原子数、
(k) は直交座標の3軸を表します。
(F_{i,j,k}) は構造 (i) 内の原子 (j) に作用する (k) 軸方向の力を表します。
応力損失は次のように表されます。
ここで、(m) は応力テンソルのVoigt指数であり、(xx) 、(yy) 、(zz) 、(yz) 、(xz) 、(xy) です。
({sigma}) は構造 (i) の応力テンソルを表します。
(c) 複数ステージの訓練#
ユーザーは訓練中に損失関数の種類と係数を変更できます。
ユーザーは複数のステージを定義し、異なるステージで異なる損失関数を使用できます。
このような手法を用いることで、訓練速度を加速することができます。
初期段階で「力」の損失に高い係数を割り当てることで、モデルの精度が向上することを検証しました。
そのため最初のステージで「力」損失に高い係数を割り当てることを推奨します。
(d) キャリブレーションステージ#
エネルギー/力/応力の損失の値は通常数桁異なります。
エネルギー損失は10-3 ~10-2 、力損失は約10-1 、応力損失は10-5 ~ 10-4 です。
これらの3つの要素の合計損失への寄与が等しくなるように、適当な損失係数を決定することは容易ではありません。
そこで、キャリブレーションステージを有効にするオプションを提供しております。
このステージでは、前のステージでのエネルギー/力/応力の損失を読み取り、損失係数を割り当てて、次の条件を満たすことを確認します。
3.3 モデルライブラリ#
訓練ジョブのステータスと訓練済みLightPFPモデルは、モデルライブラリから確認できます。
ユーザーはランチャーからモデルライブラリを開くことができます。


モデルライブラリには、訓練されたLightPFPモデルの一覧が表示されます。
モデルの詳細#
モデルライブラリには、訓練済みLightPFPモデルの情報が表示されます。

-
モデル名: 編集可能です。
-
ステータス: “Training”、”Completed”、または”Failed”のいずれかです。
-
モデルID: モデルの一意の識別子であり、訓練ジョブIDと同じです。このIDは、原子レベルのシミュレーションでモデルを使用する際に必要です。
-
経過時間: モデルのトレーニングにかかった総時間。
-
基本情報: テストセットでのモデルの平均絶対誤差(MAE)が提供されます。
-
学習曲線: 訓練中のモデルのパフォーマンスのプロット。
-
サポートされる元素: LightPFPモデルでサポートされる元素のリスト。
-
説明: モデルの説明を表示するフィールド。編集可能です。

-
ログ: トレーニングプロセスのログ。

-
モデル訓練の出力ファイル: 訓練ログとエネルギー、力、および応力の予測精度のプロットへのアクセス。たとえば、”stage2” -> “test_result.png” をダブルクリックしてモデルの予測を表示できます。
-
入力データセットの説明: 訓練に使用されたデータセットの一般情報、元素、および原子数など。

-
訓練パラメータ: JSON制御ファイルで指定された、訓練に使用されるパラメータ。
-
削除ボタン: モデルが不要になった場合にモデルを削除できます。削除されたモデルは、7日間「Trashed」パネルに移動され、その後永久に削除されます。
図とファイル#
モデルのトレーニングプロセスの理解を深め、モデルの信頼性を評価するために、
「Training logs」セクションに画像とデータファイルを含めています。
ユーザーはファイル名をダブルクリックすることでファイルをプレビューすることができます。
次に、各画像とファイルの内容について詳細な説明をします:
learning_curve.png#

この画像は、学習曲線としても知られる、テストセットにおける平均絶対誤差(MAE)の変化を表しています。
画像の青/オレンジ/緑の色は、エネルギー、力、応力の各MAEを表しています。
x軸はトレーニングのエポックを表し、y軸は対数スケールで表示されるMAEの値を表しています。
MAEの値は以下で説明するlog.fitファイルから取得できます。
グラフからは、特定のエポック(たとえば400および1200エポック)で曲線に急激な変化があることがわかります。
訓練のステージが変わりモデルの損失関数が変化したことでこのような急激な変化が発生し、
学習曲線が滑らかでなくなります。
複数ステージの訓練の詳細については、セクション3.2(c)を参照してください。
stage0、stage1、stage2のフォルダ#
デフォルトの訓練設定には3つのステージがあり、各ステージの対応する出力ファイルはstage0、stage1、stage2のフォルダに保存されます。
stage{0,1,2}/log.fit#

このファイルには、各エポックでのモデルの状態に関する詳細なデータが含まれています。各項目の説明は以下の通りです:
-
train/loss: トレーニングセットの損失値。
-
train/energy_loss: トレーニングセットのエネルギー損失。
-
train/forces_loss: トレーニングセットの力損失。
-
train/stress_loss: トレーニングセットの応力損失。
-
lr: 現在のエポックの学習率。
-
remaining_time: トレーニングプロセスの推定残り時間。
-
val/loss: テストセットの損失値。
-
val/energy_loss: テストセットのエネルギー損失。
-
val/forces_loss: テストセットの力損失。
-
val/stress_loss: テストセットの応力損失。
-
val/energy_mae: テストセットのエネルギー予測の平均絶対誤差(MAE)。
-
val/forces_mae: テストセットの力予測のMAE。
-
val/stress_mae: テストセットの応力予測のMAE。
-
epoch: 完了したエポック数。
-
iteration: トレーニングバッチのイテレーション数。
-
elasped_time: 現在のエポックの完了にかかった時間。
stage{0,1,2}/loss.png#

このグラフは、log.fitファイルからの重要な情報の視覚化です。learning_curve.pngと類似していますが、
現在のトレーニングステージの情報のみを表示しています。
stage{0,1,2}/train_result.png#

前述のように、トレーニング データセットは訓練セット (90%) とテストセット (10%) にランダムに分割されます。
この画像は、各ステージの訓練セットにおけるモデルの予測の精度を示しています。
-
左側のグラフ: トレーニング構造の各原子のポテンシャルエネルギー。
-
中央のグラフ: トレーニング構造の各原子の力のXYZ成分。
-
右側のグラフ: トレーニング構造の応力テンソルの成分(xx、yy、zz、xz、yz、xy)。
3つのサブグラフのx軸はデータセットに格納されている目標値を表し、y軸はモデルの予測値を表しています。
目標値と予測値の間のMAEは、グラフの左上に表示されます。
stage{0,1,2}/test_result.png#

この画像は、テストセットにおけるモデルの予測の精度を示しています。train_result.pngと同様の形式に従っています。
4. LightPFPモデルを用いた原子レベルのシミュレーション#
4.1 モデルの読み込み#
ASEインターフェースは、light-pfp-clientパッケージで提供されており、ユーザーはASEとmatlantis-featuresパッケージを使用して自動シミュレーションを実行できます。
LightPFPモデル「examplesv1alni3s」を使用するCalculatorを作成するには、次のようにします。
from ase.build import bulk
from light_pfp_client.estimator import Estimator
from light_pfp_client.ase_calculator import ASECalculator
calc = ASECalculator(Estimator(model_id="examplesv1alni3s"))
atoms = bulk("Al")
atoms.calc = calc
atoms.get_potential_energy()
注意: モデル「examplesv1alni3s」はNiおよびAlのみをサポートしています。
他の元素を含む場合、エラーが発生します。
4.2 matlantis-featuresでのLightPFPの利用#
LightPFPでもPFPと同様に、matlantis-featuresを使用して物性値を計算することができます。
matlantis-featuresで使用するLightPFP estimatorは、PFPと同様に estimator_fn を指定することで設定できます。
model_id や book_keeping などの基本的なパラメータは、 light_pfp_estimator_fn を使用することで簡単に設定できます。
matlantis-featuresや estimator_fn の詳細については Matlantis Guidebook の matlantis-featuresに関する説明
を参照してください。
from ase.io import read
# pfp_estimator_fnとimport pathが異なることに注意してください
from light_pfp_client.estimator_fn import light_pfp_estimator_fn
from matlantis_features.features.common.opt import FireASEOptFeature
atoms = read("AlNi3_mp-2593_conventional_standard.cif")
opt = FireASEOptFeature(
estimator_fn=light_pfp_estimator_fn(
model_id="examplesv1alni3s",
book_keeping=True,
),
)
result = opt(atoms)
計算リソースの制限により、入力構造が大きすぎると「Too big for GPU memory」というエラーが発生する可能性があることに注意してください。
入力構造サイズの上限は、LightPFP モデルの複雑さと GPU メモリの現在の状態の両方によって異なります。
このエラーが発生した場合は、入力構造のサイズを小さくしてください。
5. LightPFPモデルの評価#
light-pfp-evaluate パッケージは、実際の原子シミュレーションタスクにおけるLightPFPモデルの信頼性を評価するために設計されたパッケージです。
訓練中にテストデータに対するLightPFPモデルの精度は計算されますが、そのモデルの実際の原子シミュレーションにおけるパフォーマンスは未知です。
そこでこのパッケージでは、LightPFPモデルを用いてMDシミュレーションや物性値の計算を行い、その結果をPFPの結果と比較することでLightPFPモデルを利用する際の信頼性をテストすることができます。
5.1 CLIツール#
light-pfp-evaluate パッケージをインストールするには、以下のpipコマンドを使用してください。
pip install light-pfp-evaluate
このパッケージは、以下のようなCLIツールを提供します。
light-pfp-evaluate -c evaluate.json
ここで、 evaluate.json は評価プロセスに必要なすべてのパラメータを含む制御ファイルです。
5.2 制御ファイル#
制御ファイルは、評価に必要なすべてのパラメータを指定するJSON形式のファイルです。
まずは簡単な例から始め、その後一般的なパラメータと本パッケージで利用可能なタスクについて説明します。
制御ファイルの例#
{
"version": 2,
"initial_structure": "AlNi3_mp-2593_conventional_standard.cif",
"model_id": "examplesv1alni3s",
"pfp_model_version": "v6.0.0",
"pfp_calc_mode": "crystal_u0",
"save_path": "evaluate_result",
"phonon": {
"delta": 0.01,
"kpts": [8, 8, 8],
"supercell": [4, 4, 4]
},
"md":[
{
"supercell": [3, 3, 3],
"temperatures": [1500.0],
"steps": [2000],
"pressures": [10.0],
"timestep": 1.0,
"reuse_traj": true
},
{
"supercell": [5, 5, 5],
"temperatures": [500.0, 1000.0],
"steps": [2000, 2000],
"pressures": [1.0, 1.0],
"timestep": 1.0,
"reuse_traj": true
}
]
}
この例では、以下のようにモデル評価のタスクが実行されます:
-
“examplesv1alni3s”というLightPFPモデルと、PFPバージョン6.0.0のモデルを crystal_u0 計算モードで比較します。
-
Ni3Al結晶を対象の材料として、両方のモデルを使用してフォノン計算およびMD計算を実施します。
-
MD計算には以下の3つのタスクが含まれます
-
3x3x3のスーパーセル、1500Kの温度、10バールの圧力
-
5x5x5のスーパーセル、500Kの温度、1バールの圧力
-
5x5x5のスーパーセル、1000Kの温度、1バールの圧力
-
-
全ての計算および比較分析の結果は、 evaluate_result フォルダに保存されます。
一般的なパラメータ#
-
initial_structure(List[str], Required):-
初期構造へのパス(例えばCIF形式)。複数の初期構造をサポートしています。
-
model_id(str, Required):-
評価対象のLightPFPモデルID。
-
pfp_model_version(str, Required):-
比較対象となるPFPモデルのバージョン。
-
pfp_calc_mode(str, Required):-
PFPモデルの計算モード。
-
save_path(str, Required):-
評価結果を保存するディレクトリ。
利用可能なタスク#
light-pfp-evaluate パッケージでは以下の7つのタスクを実行することができます。
-
md (Molecular Dynamics): MDシミュレーションでLightPFPモデルの性能を評価します。
-
eos (Equation of State): エネルギー体積曲線の予測精度を評価します。
-
lattice: 格子定数の予測精度を評価します。
-
elastic: 弾性特性の予測精度を評価します。
-
phonon: フォノン特性の予測精度を評価します。
-
vacancy: 欠陥形成エネルギーの予測精度を評価します。
-
surface: 表面エネルギーの予測精度を評価します。
これらのタスクは、制御ファイル内で対応するキーに対して true / false を設定し、必要なオプションを与えることで有効/無効にすることができます。
各タスクがどのように実行されるかの詳細については、次のセクション「タスク」で説明します。
5.3 タスク#
md (Molecular dynamics)#
このタスクでは、MDシミュレーションを指定された条件下で実行し、Lightモデルの動的シナリオにおける性能を評価します。
制御ファイルの initial_structure パラメータで初期構造を定義します。
MDシミュレーションの詳細は md パラメータで制御されます。以下は md の例です:
{
"version": 2,
"initial_structure": "AlNi3_mp-2593_conventional_standard.cif",
"model_id": "examplesv1alni3s",
"pfp_model_version": "v6.0.0",
"pfp_calc_mode": "crystal_u0",
"save_path": "evaluate_result",
"md": {
"supercell": [3, 3, 3],
"temperatures": [1500.0],
"steps": [2000],
"pressures": [10.0],
"timestep": 1.0,
"reuse_traj": true
}
}
パラメータ説明:
-
supercell(List[int], Required):-
MDシミュレーションで使用するスーパーセルのサイズ。
-
temperatures(List[float], Required):-
MDシミュレーションの温度のリスト (K単位)。
-
steps(List[int], Required):-
各温度におけるMDステップ数。
-
pressures(List[float], Required):-
各温度における圧力のリスト (バール単位)。
-
timestep(float, Required):-
MDシミュレーションにおけるタイムステップ (フェムト秒単位)。
-
reuse_traj(bool, Required):-
true がセットされた場合、 save_path ディレクトリ内にトラジェクトリが存在すればそのトラジェクトリを再利用します。
false がセットされた場合、新しいトラジェクトリが作成されます。
アウトプット:
MDシミュレーションの結果は save_path で指定されたディレクトリに保存されます。MDシミュレーションの出力は以下の通りです:
-
MD トラジェクトリ: save_path ディレクトリ内に保存されます
-
トラジェクトリの分析結果:
-
ポテンシャルエネルギーと体積の時間変化
-
原子の平均二乗変位(MSD)
-
原子の動径分布関数(RDF)
-
LightPFPモデルおよびPFPモデルの結果がプロットされ、以下のように保存されます:
-
md.png: ポテンシャルエネルギーと体積変化

-
msd.png: 平均二乗変位

-
rdf.png: 動径分布関数

eos (Equation of State)#
eos タスクでは、結晶構造の体積とポテンシャルエネルギーの関係を評価します。
このタスクによって、異なる体積下における構造特性を予測する能力を評価することができます。
手順:
-
fmax=0.01 でFIREオプティマイザを使用し、原子位置および格子定数の両者に対して構造最適化を行います。
-
初期構造は格子ベクトルに沿って一様に伸長もしくは圧縮されます。変位の幅は初期の格子ベクトルの-5%から+5%です。データポイントはこの範囲内で1%の間隔で計算されます。
-
変位を加えた各構造に対して、ジオメトリ最適化が実行されます。 fmax=0.01 でFIREオプティマイザを使用し、セルの体積を固定した上で原子位置と格子定数が最適化されます。
-
最適化された各構造に対してポテンシャルエネルギーを計算します。
-
このプロセスをLightPFPモデルとPFPモデルの両方を使用して繰り返します。
パラメータ:
{
"version": 2,
"initial_structure": "AlNi3_mp-2593_conventional_standard.cif",
"model_id": "examplesv1alni3s",
"pfp_model_version": "v6.0.0",
"pfp_calc_mode": "crystal_u0",
"save_path": "evaluate_result",
"eos": true
}
アウトプット:
本タスクの計算結果は、 save_path で指定されたディレクトリに保存されます。
-
eos.png: LightPFPおよびPFPから得られたエネルギー体積曲線を比較するグラフ。グラフによる視覚的な表現によって、2つのモデルの予測結果を簡単に比較することができます。

-
eos.dat: 以下を含むデータファイル:
-
LightPFPおよびPFPによるEOS曲線から計算された体積弾性率
-
両者のモデルにおける平衡状態での体積
-
PFPに対するLightPFPの予測誤差
-
eos.datファイルの例:
LightPFP PFP err rel err
-- ---------- ------- --------- -----------
B 182.814 187.459 4.64441 0.0247757
V0 45.3276 45.311 0.0166668 0.000367831
lattice#
lattice タスクでは、最適化された結晶構造の格子定数を予測した際のモデルの性能を評価します。
このタスクでは、原子位置と格子定数の両者をLightPFPおよびPFPで最適化した後に、格子定数を直接比較します。
手順:
-
initial_structure で指定された初期構造をスタート地点として使用します。
-
fmax=0.01 でFIREオプティマイザを使用し、原子位置および格子定数の両者に対して構造最適化を行います。
-
最適化は、LightPFPとPFPの両方を使用して独立に行われます。
-
両モデルによる構造最適化後の構造を比較します。
パラメータ:
{
"version": 2,
"initial_structure": "AlNi3_mp-2593_conventional_standard.cif",
"model_id": "examplesv1alni3s",
"pfp_model_version": "v6.0.0",
"pfp_calc_mode": "crystal_u0",
"save_path": "evaluate_result",
"lattice": true
}
アウトプット:
本タスクの結果は、 save_path で指定されたディレクトリに保存されます。
-
lattice.dat: 以下を含むデータファイル:
-
LightPFPおよびPFPで最適化された構造の3つの格子ベクトルの長さ (a、b、c)
-
LightPFPおよびPFPで最適化された構造の3つの格子ベクトルの角度 (α, β, γ)
-
これらの格子定数に対するLightPFPとPFPの予測誤差および相対誤差
-
lattice.datファイルの例:
LightPFP PFP err rel err
----- ---------- -------- ----------- -----------
a 3.56479 3.56538 0.000592517 0.000166186
b 3.56479 3.56538 0.000592569 0.000166201
c 3.56479 3.56538 0.000592561 0.000166199
alpha 90 90 3.94905e-08 4.38783e-10
beta 90 90 3.35577e-07 3.72863e-09
gamma 90 90 9.73355e-08 1.08151e-09
elastic#
elastic タスクでは、LightPFPモデルが材料の弾性テンソルおよびそこから導出される弾性特性を予測する能力を評価します。
このタスクにより、LightPFPモデルが結晶構造の機械特性を予測する際の精度を評価することができます。
手順:
弾性特性の計算は、matlantis-featuresパッケージの ElasticTensorFeature と PostElasticPropertiesFeature を使用して行われます。
このプロセスは以下の手順を含みます。
-
fmax=0.01 でFIREオプティマイザを使用し、原子位置および格子定数の両者に対して構造最適化を行います。
-
matlantis-featuresを使用して、弾性テンソルと弾性特性を計算します。
計算手法に関するより詳細な情報については、 Matlantis Guidebook を参照してください。
パラメータ:
{
"version": 2,
"initial_structure": "AlNi3_mp-2593_conventional_standard.cif",
"model_id": "examplesv1alni3s",
"pfp_model_version": "v6.0.0",
"pfp_calc_mode": "crystal_u0",
"save_path": "evaluate_result",
"elastic": true
}
アウトプット:
本タスクの計算結果は、 save_path で指定されたディレクトリに保存されます。
-
elastic.dat: 以下の情報を含むデータファイル:
-
LightPFPおよびPFPで予測された弾性テンソルの各要素 (例:C11、C12、C13など)
-
弾性テンソルから導出される以下の弾性特性:
-
体積弾性率
-
剪断弾性係数
-
ヤング率
-
ポアソン比
-
-
すべての弾性特性に対するLightPFPの予測値の、PFPの予測値に対する絶対誤差と相対誤差
-
elastic.datファイルの例:
LightPFP PFP err rel err
------------- ---------- ---------- ---------- ---------
C11 252.468 246.462 6.00637 0.0243704
C12 157.965 156.013 1.9518 0.0125105
C13 157.964 156.013 1.95175 0.0125102
C22 252.468 246.461 6.0072 0.0243738
C23 157.965 156.013 1.95195 0.0125115
C33 252.468 246.464 6.00388 0.0243601
C44 124.497 118.101 6.39594 0.0541565
C55 124.497 118.1 6.39647 0.0541613
C66 124.497 118.101 6.39589 0.0541561
bulk_modulus 189.466 186.163 3.30316 0.0177434
shear_modulus 84.4367 80.3815 4.0552 0.0504494
young_modulus 220.547 210.804 9.7432 0.0462192
poisson_ratio 0.305992 0.311272 0.00528048 0.0169642
phonon#
phonon タスクでは対象の結晶構造の振動特性を予測することでモデルの性能を評価します。
このタスクでは、matlantis-featuresパッケージのいくつかの機能を使用してフォノン特性を計算し、LightPFPモデルとPFPモデルを比較します。
手順:
-
初期構造の最適化
-
fmax=0.01 でFIREオプティマイザを使用し、原子位置および格子定数の両者に対して構造最適化を行います。
-
最適化中に初期構造の対称性を維持することで、フォノン分散スペクトルを比較可能にします。
-
-
フォノン計算:
-
ForceConstantFeature を使用して力定数を計算します。
-
PostPhononBandFeature を使用してフォノン分散を計算します。
-
PostPhononDOSFeature を使用してフォノン状態密度(DOS)を計算します。
-
フォノン計算結果から熱力学的特性を導出するために、 PostPhononThermochemistryFeature を使用します。
-
計算手法に関するより詳細な情報は、 the Matlantis Guidebook を参照してください。
パラメータ:
本タスクは、制御ファイルの phonon セクション内の以下のパラメータによって制御されます:
{
"version": 2,
"initial_structure": "AlNi3_mp-2593_conventional_standard.cif",
"model_id": "examplesv1alni3s",
"pfp_model_version": "v6.0.0",
"pfp_calc_mode": "crystal_u0",
"save_path": "evaluate_result",
"phonon": {
"delta": 0.01,
"kpts": [8, 8, 8],
"supercell": [4, 4, 4]
}
}
パラメータ説明:
-
delta(float, Required):-
有限差分法における変位距離(オングストローム単位)。
-
kpts(List[int], Required):-
フォノン計算の際にブリルアンゾーンをサンプリングするためのK点メッシュ。
-
supercell(List[int], Required):-
フォノン計算に使用されるスーパーセルの次元。
アウトプット:
本タスクの結果は、 save_path で指定されたディレクトリに保存されます。出力には以下が含まれます:
-
phonon.png: フォノン分散スペクトルの予測結果をLightPFPとPFPで比較したグラフ。
左の図はブリルアンゾーン内の高対称性パスに沿ったフォノン分散を示し、右の図はフォノン状態密度(DOS)を示します。
下の図はフォノン計算から導出される熱力学的特性を示し、熱容量(Cv)、エントロピー(S)、内部エネルギー(U)、自由エネルギー(F)を示します。
LightPFPの結果は実線で、PFPの結果は破線で表示されます。

vacancy#
vacancy タスクでは、結晶構造に空孔を作成するために必要なエネルギーを予測した際のモデルの性能を評価します。
このタスクでは、LightPFPモデルとPFPモデルが、構造内の各原子位置に対してポテンシャルエネルギーを計算する性能を比較します。
手順:
-
初期構造内の各原子位置に対して:
-
空孔を作成するために原子を除去します
-
fmax=0.01 でFIREオプティマイザを使用し、原子位置および格子定数の両者に対して構造最適化を行います
-
最適化された欠陥構造のポテンシャルエネルギーを計算します
-
-
このプロセスをLightPFPモデルとPFPモデルの両者を使用して繰り返します
-
両モデルによって予測されたポテンシャルエネルギーを比較します
パラメータ:
本タスクは、制御ファイルの vacancy セクション内の以下のパラメータによって制御されます:
{
"version": 2,
"initial_structure": "AlNi3_mp-2593_conventional_standard.cif",
"model_id": "examplesv1alni3s",
"pfp_model_version": "v6.0.0",
"pfp_calc_mode": "crystal_u0",
"save_path": "evaluate_result",
"vacancy": {
"supercell": [2, 2, 2]
}
}
パラメータ説明:
-
supercell(List[int], Required):-
空孔計算に使用されるスーパーセルの次元。この値により、空孔の鏡像間の相互作用を減らし、より大きな周期系における空孔効果を予測することができます
アウトプット:
本タスクの結果は、 save_path で指定されたディレクトリに保存されます。出力には以下が含まれます:
-
vacancy.dat: 以下を含むデータファイル:
-
LightPFPおよびPFPで計算された各原子位置に対する空孔形成エネルギー
-
PFPの計算結果に対するPFPの予測誤差と相対誤差
-
vacancy.datファイルの例:
LightPFP PFP err rel err
--- ---------- ------- --------- ----------
Al0 7.07318 7.05132 0.0218594 0.00310004
Ni1 6.38666 6.41616 0.0295055 0.00459862
Ni2 6.38666 6.41616 0.0295022 0.00459811
Ni3 6.38666 6.41616 0.029502 0.00459808
-
vacancy.png: 各原子位置に対する、LightPFPとPFPによって予測された空孔形成エネルギーの比較グラフ

surface#
surface タスクでは、様々な結晶表面を作成するために必要なエネルギーを予測する能力を評価します。
このタスクでは、LightPFPモデルとPFPモデルが異なるミラー指数面に対して表面エネルギーを計算した際の性能を比較します。
手順:
-
初期構造から始めて、様々なミラー指数面に対して表面構造を作成します。
ミラー指数の範囲は max_index パラメータによって決定されます。
対称性の分析によって重複する表面を除外します。 -
fmax=0.01 でFIREオプティマイザを使用し、原子位置および格子定数の両者に対して表面構造の最適化を行います。
最適化された表面に対してポテンシャルエネルギーを計算します。 -
この手順をLightPFPモデルとPFPモデルの両者を使用して繰り返します。
-
両モデルによって予測された表面エネルギーを比較します。
パラメータ:
本タスクは、制御ファイルの surface セクション内の以下のパラメータによって制御されます:
{
"version": 2,
"initial_structure": "AlNi3_mp-2593_conventional_standard.cif",
"model_id": "examplesv1alni3s",
"pfp_model_version": "v6.0.0",
"pfp_calc_mode": "crystal_u0",
"save_path": "evaluate_result",
"surface": {
"max_index": 2
}
}
パラメータ説明:
-
max_index(int, Required):-
表面を生成する際の最大ミラー指数。例えば2に設定すると、対称性の観点から等価な面を除いて、(100)から(221)までの表面が計算に含まれます。
アウトプット:
本タスクの結果は、 save_path で指定されたディレクトリに保存されます。出力には以下が含まれます:
-
surface.dat: 以下を含むデータファイル:
-
LightPFPおよびPFPで計算された各ミラー指数面に対する表面エネルギー
-
PFPの予測値に対するLightPFPの予測誤差と相対誤差
-
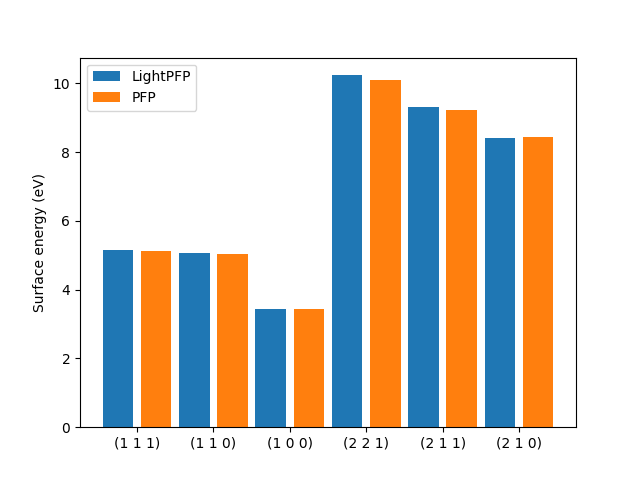
surface.datファイルの例:
LightPFP PFP err rel err
------- ---------- -------- --------- ----------
(1 1 1) 5.16242 5.12795 0.0344731 0.00672259
(1 1 0) 5.0675 5.0406 0.0268934 0.00533534
(1 0 0) 3.44917 3.42469 0.0244773 0.0071473
(2 2 1) 10.2329 10.0984 0.134477 0.0133167
(2 1 1) 9.30585 9.20921 0.0966463 0.0104945
(2 1 0) 8.41813 8.4292 0.0110688 0.00131315
-
surface.png: 各ミラー指数面に対する、LightPFPとPFPによって予測された表面エネルギーの比較グラフ
5.4 Python APIの使用方法#
CLIに加えて、 light-pfp-evaluate パッケージでは各評価タスクに対してPython API(Python関数)が提供されています。
これらのAPIを用いることで、LightPFPモデルの評価プロセスをPythonスクリプトもしくはJupyter notebookと統合することができ、より柔軟にプログラムからモデル評価を制御することができます。
これらのPython APIを利用するためには、LightPFPおよびPFPの estimator_fn を作成する必要があります。
これは内部でmatlantis-featuresを使用するために estimator_fn が必要なためです。
estimator_fn に関する説明は、 Matlantis Guidebook の estimator_fnに関する説明 を参照してください。
以下に示すコードは、PythonAPIを使用して弾性特性に対する評価を行う簡単な例です。
from ase.io import read
from matlantis_features.utils.calculators.pfp_api_calculator import pfp_estimator_fn
from pfp_api_client.pfp.estimator import EstimatorCalcMode
from light_pfp_client.estimator_fn import light_pfp_estimator_fn
from light_pfp_evaluate import evaluate_elastic
# Define estimator functions for PFP and LightPFP
estimator_fn_pfp = pfp_estimator_fn(model_version="v6.0.0", calc_mode=EstimatorCalcMode.CRYSTAL_U0)
estimator_fn_light_pfp = light_pfp_estimator_fn(model_id="examplesv1alni3s")
# Read the initial structure
atoms = read("AlNi3_mp-2593_conventional_standard.cif")
# Perform elastic property evaluation
evaluate_elastic(
atoms,
estimator_fn_pfp,
estimator_fn_light_pfp,
save_result="validate_results/elastic.dat"
)
この例では以下のことを実行しています:
-
必要なモジュールと関数をimportします。
-
PFPおよびLightPFPに対して estimator_fn を定義します。
-
初期構造をCIFファイルから読み込みます。
-
初期構造、LightPFPおよびPFPの estimator_fn 、結果を保存するディレクトリを指定して evaluate_elastic 関数を呼び出します。
「タスク」セクションで説明した他の評価タスクについても、同様のPython APIが利用可能です。
-
evaluate_md : MDシミュレーション
-
evaluate_eos : 状態方程式
-
evaluate_lattice : 格子定数
-
evaluate_phonon : フォノン計算
-
evaluate_vacancy : 空孔形成エネルギー
-
evaluate_surface : 表面エネルギー
各Python APIは弾性特性の例と同様に、初期構造、LightPFPモデルおよびPFPモデルの estimator_fn 、そして各評価タスクに対して必要なパラメータを引数として渡すことで利用可能です。
より詳細な情報については、 light-pfp-evaluate パッケージのソースコードを参照してください。
6. (応用編) LightPFPモデル訓練のオプション#
我々のベンチマークでは、事前学習済みモデルを使用することがLightPFPモデルの訓練に最も効率的な方法であることが示されています。
しかし、以下に示すケースでは事前学習済みモデルを使用せずにLightPFPモデルを訓練することが有用な場合があります。
そのようなケースに対して、LightPFPでは既存のモデルからモデルを訓練する方法や、スクラッチで訓練する方法を提供しています。
既存のモデルからの訓練が有用な場合:
作成したLightPFPモデルが実用に耐える精度ではない際、データポイントを追加してモデルを再訓練する必要があるかもしれません。
そのようなケースでは、前回のモデルをベースにして継続して学習を行うことで、前段のモデル学習の成果を活かすことができます。
スクラッチでの訓練が有用な場合:
事前学習済みモデルは適切な初期パラメータを提供し、モデルの収束を効率的に行うことができます。
しかしながら、levmaxやcutoffなどのパラメータを含むモデルのアーキテクチャを変更することはできません。
そこで、異なるアーキテクチャを使用したい場合(例えば事前学習済みモデルが十分な精度を提供しない場合など)は、スクラッチから訓練することでモデルのアーキテクチャを自分で定義することができます。
本章の後半では、既存のモデルからモデルを訓練する方法や、スクラッチで訓練する方法について詳しく説明します。
6.1 既存のモデルからの訓練#
以下は、既存のモデルから訓練するための制御ファイルの例です。
{
"common_config": {
"total_epoch": 200,
"reload_model": "examplesv1alni3s"
}
}
制御ファイルのパラメータ#
-
reload_model(str):-
継続して訓練する既存モデルのID。訓練ジョブはそのモデルから開始されます。
例の制御ファイルの説明#
この例では、指定されたreload_model IDに基づいて、モデルライブラリから指定されたLightPFPモデルがダウンロードされます。モデルのハイパーパラメータ(levmaxやpretrained_modelなど)はダウンロードされたモデルから継承されるため、これらを指定する必要はありません。
ダウンロードされたLightPFPモデルは、指定されたエポック数(total_epoch)分、追加で訓練を行います。訓練プロセスは 3.1 はじめに の例と同じく、複数のステージから構成されます。
6.2 スクラッチでの訓練#
事前学習済みモデルはLightPFPモデルの訓練に適切な初期パラメータを提供しますが、一部のMTPハイパーパラメータは固定されています。
levmaxなどのMTPハイパーパラメータを調整する場合は、事前学習済みモデルを使用せずにこれらのハイパーパラメータを指定する必要があります。
スクラッチで訓練する場合、事前学習済みモデルよりも大きな訓練データセットを使用し、より多くのエポックで訓練することをお勧めします。
以下は、制御ファイルの例です。
{
"common_config": {
"total_epoch": 400,
"lr_scheduling": "step"
},
"mtp_config": {
"pretrained_model": "",
"rc": 6.5,
"levmax": 20,
"n_q": 16,
"moment_init_cost": 2,
"moment_mu_cost": 4,
"moment_nu_cost": 1
}
}
制御ファイルのパラメータ#
-
lr_scheduling(str, Optional, default=”linear_warmup”):-
学習率スケジューラ。サポートされているオプションは “step”、”linear_warmup”、”None” です。
-
pretrained_model(str, Optional, default=””):-
スクラッチで訓練するためには、上記の様に””を指定するか、もしくはこのフィールドを制御ファイルから削除します。
注: このフィールドが指定されている場合、事前学習済みモデルを使用しての学習と見なされてしまい、mtp_configセクションのmodel_version以外の項目は無視されます。
-
rc(float, Optional, default=6.0):-
1つの原子の局所環境を定義するためのカットオフ距離
-
levmax(int, Optional, default=8):-
モーメント記述子の複雑さを制御する引数。”levmax” パラメータが大きいほど、MTPモデルはより複雑になります。通常、levmaxの範囲は2〜29です。
-
n_q(int, Optional, default=16):-
動径関数を記述するために使用されるChebyshev多項式の数。
-
moment_mu_cost(int, Optional, default=4):-
モーメントM(𝜇, 𝜈)のレベルを計算する際の、𝜇のコスト係数。コストはモーメントの𝜇と𝜈の値には依存しません。”level = moment_init_cost + moment_mu_cost * 𝜇 + moment_nu_cost * 𝜈”
詳細については、 1.2 サポートする手法 を参照してください。
-
moment_init_cost(int, Optional, default=2):-
モーメントM(𝜇, 𝜈)のレベルを計算する際に使用される初期コスト。
-
moment_nu_cost(int, Optional, default=1):-
モーメントM(𝜇, 𝜈)のレベルを計算する際の、𝜈のコスト係数。
例の制御ファイルの説明#
この例は 3.1 はじめに で取り上げた例と似ていますが、mtp_configで指定されたハイパーパラメータに基づいてLightPFPモデルが作成されます。
パラメータはランダムに初期化されます。
訓練プロセスは、前の例と同様に複数のステージから構成されます。ただし最初のステージでは、初期モデルがランダムなパラメータを持っているため、”step”学習率スケジューラが使用されます。デフォルトでは、事前学習済みモデルをファインチューニングする場合には “linear_warmup” が使用されます。
スクラッチから訓練することも可能ですが、できるだけ事前学習済みモデルを使用することをお勧めします。通常、事前学習済みモデルを使用する方が精度と信頼性が高くなります。事前学習済みモデルを用いた訓練とスクラッチからの訓練との比較を、 付録2: 事前学習済みモデルのベンチマーク結果 に記載しました。
7. (応用編) LightPFPの推論速度向上#
この章では、LightPFPで作成したモデルを効率よく使用し、推論やMDシミュレーションを実施するためのプラクティスを紹介します。
7.1 並列実行#
ノートブックのバックグラウンド実行や、joblibなどの並列計算ライブラリを使用することで複数の推論やMDシミュレーションを同時に実行することができます。
しかしながら、現在LightPFPは並列計算のための最適化がなされておらず、タスクに必要な総処理時間は並列計算を実施しても大きく改善されません。
また、LightPFPでは推論をする際に必要な情報(モデルのパラメータや、後述するブックキーピングで使用される隣接情報を指します)をサーバーにキャッシュしており、同時にキャッシュできる数に上限を設けています。(現在は10が上限です)。
この設計は推論に割り当て可能なメモリ量を確保するための措置であり、同時にその上限数以上のMDシミュレーションを実行することは推奨されていません。
なぜなら、上限より多いモデルを同時に使用した場合、各推論の度に必要な情報を再度メモリにロードし、不要な情報を削除する処理が発生してしまい、パフォーマンスが低下するためです。
なお、モデル情報は各Estimatorインスタンスごとに保存されており、同じLightPFPモデルを使用したとしても、異なるEstimatorインスタンスを使用する場合は別々にキャッシュされます。
よって、パフォーマンスの低下を防ぐために、上限(10個)より多くの推論ジョブやMDシミュレーションを同時に実行することは避けることが推奨されます。
並列処理を実施した際の詳細な情報やベンチーマーク結果については、 付録4: 並列実行のベンチマーク を参照してください。
7.2 ブックキーピング#
MDシミュレーションの高速化のために、LightPFPモデルではブックキーピングというオプションを提供しています。
ブックキーピングは、MDシミュレーションソフトウェアで一般的に使用されるテクニックです。
ブックキーピング法は、MDシミュレーション中の前処理ステップの繰り返しを最小限に抑えるために、隣接情報を保存します。
多くの場合、ブックキーピング法を使用することでMDシミュレーションに必要な時間が大幅に短縮されます。
ブックキーピング法では、ユーザー定義のカットオフ距離内だけでなく、追加のマージン内の隣接情報も収集します。
MDシミュレーションの領域内に類似した構造の連続した系列がある場合、隣接情報を再構築する必要がありません。
これにより、隣接情報の構築頻度が減少し、MDの速度が向上します。
追加のマージンを超えて原子が移動した場合にのみ、隣接情報が再構築されます。
ブックキーピング機能の有効化/無効化#
ブックキーピングを有効にすることで基本的にはパフォーマンスの向上が見込まれるため、LightPFPではデフォルトでブックキーピングを有効にしています。
ブックキーピングを無効化したい場合は、Estimatorを初期化する際に book_keeping=False を設定してください。たとえば、以下のように設定します。
from ase.build import bulk
from light_pfp_client.estimator import Estimator
from light_pfp_client.ase_calculator import ASECalculator
estimator = Estimator(model_id="examplesv1alni3s", book_keeping=False)
calc = ASECalculator(estimator)
また、サーバーに保存されている隣接情報の削除は、シミュレーション後に次のように行います。
estimator.clean_up()
次の計算でメモリの不必要な占有や他のパフォーマンスの低下を防ぐために、実行が終了したらすぐに隣接情報を削除することをお勧めします。
ブックキーピング利用の注意点#
上記のように、ブックキーピング法で使用されるカットオフ距離は、追加のマージンの距離だけユーザー定義の値よりも大きくなります。
そのため単一の前処理ステップにかかる時間は長くなりますが、ほとんどのケースでは隣接情報の再利用により前処理の頻度が減少することが期待されます。
よって、多くのケースではブックキーピングを有効にすることでMDシミュレーション全体の処理時間が短縮されることが期待されます。
しかし、ブックキーピングを有効にすることで推論に利用可能なメモリが少なくなる点には注意が必要です。
ブックキーピングを有効にすることでサーバーのメモリが隣接情報の保持のために占有され、結果としてブックキーピングを有効にしない場合よりも計算可能な最大原子数が減少する可能性があります。
特に、多くのモデルを同時に使用してMDシミュレーションを実行する場合では隣接情報の保持に必要なメモリも増加し、計算可能な最大原子数がさらに減少します。
ブックキーピングによる計算可能な最大限原子数への影響についての詳細な情報は、 付録4: 並列実行のベンチマーク を参照してください。
また、同時に10個以上のMDシミュレーションを行う際にも注意が必要です。
7.1 並列実行 で述べたように、現在LightPFPではサーバーに同時にキャッシュすることができる推論に必要な情報(モデルのパラメータや隣接情報など)の数に10個という上限を設けています。
そのため、10個より多くのジョブをブックキーピングを有効にして同時に実行しても、隣接情報の再作成や削除が発生し、隣接情報を期待通りに再利用することができず、ブックキーピングによるパフォーマンス向上が得られない可能性があります。
7.3 推奨設定#
基本的にはブックキーピングを有効にすることでMDシミュレーションの高速化が期待できるため、ブックキーピングを有効にすることをお勧めします。
一方で上述のように現在のLightPFPサーバーの仕様から、10個を超えるジョブを同時に実行する場合にはブックキーピングによるパフォーマンスの向上は期待できないです。
そのため、MDシミュレーションの実行に必要な合計時間を最小化するためには、基本的にはブックキーピングを有効にすることをお勧めしますが、10個を超えるジョブを同時に実行しないように注意してください。
もし10個を超えるジョブを実行したい場合には、ジョブを10個ずつに分割し、それらを順番に実行してください。
また、計算可能な原子数がブックキーピングによって減少する可能性があるため(特に並列で複数のジョブを実行する場合)、計算可能な原子数が重要な場合には並列で実行するジョブの数を減らすことを検討してください。
8. 参考文献#
-
[Novikov, I. S., et al. Mach. Learn. Sci. Technol. 2, 025002 (2021)] (https://iopscience.iop.org/article/10.1088/2632-2153/abc9fe)
-
[Kingma, Diederik P. and Jimmy Ba. “Adam: A Method for Stochastic Optimization.” CoRR abs/1412.6980 (2014)] (https://arxiv.org/abs/1412.6980)
9. 付録#
付録1: 訓練用制御ファイルの高度な使用法#
訓練用制御ファイルの全パラメータ#
{
"common_config": {
"total_epoch": null,
"batch_size": 128,
"reload_model": null,
"lr_scheduling": "linear_warmup",
"max_energy": 1e38,
"max_forces": 1e38
},
"mtp_config": {
"model_version": "v1.0",
"pretrained_model": "ALL_ELEMENTS_SMALL_6"
},
"multistage_config": {
"lr_list": [0.1, 0.01],
"epoch_list": [80, 160],
"energy_loss_coeff_list": [1e-05, 1.0],
"forces_loss_coeff_list": [10.0, 0.1],
"stress_loss_coeff_list": [1e-05, 10.0],
"loss_func_list": ["mse", "mse"],
"use_calib_stage": true,
"calibration_lr": 0.01,
"calibration_epoch": 80
}
}
例の説明#
上記の制御ファイルの例を用いて、訓練ジョブがどのように動作するかを説明します。
-
最初に、”mtp_config”に従ってlight PFPモデルが初期化されます。コードはMTPアーキテクチャであることを識別し、指定された事前学習済みモデル”ALL_ELEMENTS_SMALL_6”でMTPモデルが初期化されます。
Note
“ORGANIC”など特定の事前学習済みモデルは、元素数に制限があります。サポートされていない元素でモデルを訓練しようとすると、エラーが発生します。
-
複数段階の訓練が開始されます。最初の段階では、学習率は0.1で、エネルギー/力/応力損失の係数はそれぞれ1e-5、10.0、1e-5です。主に力に対する性能を向上させるため、エネルギーと応力の係数はほぼ0に設定されています。このような戦略によって、高品質のlight PFPモデルを効果的に得ることができます。データセットは最初にスキャンされ、最大エネルギー/力を超えるデータポイントが削除され、次にトレーニングセットとテストセットに分割されます。トレーニングセットは、128個の構造を含むミニバッチでMTPモデルに渡されます。
-
最初の段階が終了した後、異なる損失係数、学習率、学習率スケジューラで第2段階が開始されます。最初の段階の学習でパラメータ空間の適当な領域に収束しているため、この段階では学習率は最初の段階よりも小さい0.01に設定されています。
-
“use_calib_stage”がtrueであるため、最後にキャリブレーションステージが実行されます。第2段階のトレーニングログが分析され、エネルギー/力/応力の損失の寄与がほぼ等しくなるように、3つの損失係数が自動的に割り当てられます。
パラメータの説明#
共通設定
訓練タスクの基本的な引数です。
-
total_epoch(int, Optional):-
複数段階の訓練プロセス全体が実行されるエポック数。stage1/stage2/calibrationステージのそれぞれに対し、0.25:0.5:0.25の比率で分割されます。
-
batch_size(int, Optional):-
1回のパラメータ更新に使用されるトレーニング構造の数。
-
reload_model(str, Optional):-
モデルIDが指定されている場合、指定されたモデルから訓練ジョブが開始されます。空の場合、モデルのパラメータがランダムに初期化されます。
-
lr_scheduling(str, Optional):-
学習率スケジューラ。”step”、”linear_warmup”、”None”をサポートしています。
-
scheduler_step_size`(int, Optional):-
スケジューラのステップサイズ。デフォルト値はint(epoch / 25)です。
-
max_energy(float, Optional):-
訓練データセットで許容される1原子あたりの最大エネルギー。エネルギーがこの値より大きい場合、構造はスキップされます。
-
max_forces(float, Optional):-
訓練データセットで許容される最大の力。1原子に作用する力がこの値より大きい場合、構造はスキップされます。
モデル: MTP設定
MPTモデルの複雑性を定義するための引数です。
-
model_version(str, Optional):-
MTPモデルのバージョン。現在、”v1.0”のみがサポートされています。
-
pretrained_model(str, Optional):-
事前学習済みモデルを使用します。サポートされている事前学習済みモデルは、 (a) 事前学習済みモデル セクションにリストされています。空の場合、事前学習済みモデルは使用されません。デフォルトは “” です。
Note
このフィールドが指定されている場合、mtp_configセクションのmodel_version以外の残りのフィールドは無視されます。
[オプション] 次の引数はスクラッチでMTPモデルを訓練する場合にのみ使用されます(詳細については、 6.2 スクラッチでの訓練 セクションを参照してください)。
-
rc(float, Optional):-
1原子の局所環境を定義するためのカットオフ距離。
-
levmax(int, Optional):-
モーメント記述子の複雑性を制御する引数。 “levmax”パラメータが大きいほど、MTPモデルはより複雑になります。
-
n_q(int, Optional):-
MTPの動径関数を記述するために使用されるChebyshev多項式の数。
-
moment_mu_cost(int, Optional):-
モーメントM(𝜇, 𝜈)のレベルを計算する際の𝜇のコスト係数。コストはモーメントのmuとnuの値には依存しません。
-
moment_init_cost(int, Optional):-
モーメントM(𝜇, 𝜈)のレベルを計算する際に使用される初期コスト。
-
moment_nu_cost(int, Optional):-
モーメントM(𝜇, 𝜈)のレベルを計算する際の𝜈のコスト係数。
-
nn_dim_list(List[int], Optional):-
ニューラルネットワークの各層のニューロン数。リストの長さは層の数を表します。
デフォルトは []で、この場合は線形関数が readout 関数に使用されます。
空でない場合、ニューラルネットワークが readout 関数に使用されます。
Note
推奨される隠れ層の数は2〜3層で、各層のニューロン数は16〜128です。
複数段階の訓練
訓練タスクの引数です。 “lr_list”、”epoch_list”、”energy_loss_coeff_list”、”forces_loss_coeff_list”、”stress_loss_coeff_list”、”loss_func_list”の要素数を等しくする必要があります。
-
lr_list(List[float], Optional):-
学習率のリスト。i番目の要素はi番目のステージの学習率です。
-
epoch_list(List[int], Optional):-
各ステージのトレーニングエポック数。
-
energy_loss_coeff_list(List[float], Optional):-
各ステージのエネルギー損失の係数。
-
forces_loss_coeff_list(List[float], Optional):-
各ステージの力損失の係数。
-
stress_loss_coeff_list(List[float], Optional):-
各ステージの応力損失の係数。
-
loss_func_list(List[str], Optional):-
各ステージでエネルギー/力/応力損失を評価するための損失関数。”mse”、”l1”をサポートします。
-
use_calib_stage(bool, Optional):-
キャリブレーションステージを使用するかどうか。
-
calibration_lr(float, Optional):-
キャリブレーションステージの学習率。
-
calibration_epoch(int, Optional):-
キャリブレーションステージのエポック数。
付録2: 事前学習済みモデルのベンチマーク結果#
ケース1: Ni3Al#
-
データセットの準備
-
小規模データセット: 519構造
-
大規模データセット: 1987構造
-
-
LightPFPモデルの準備
-
例と同様に、3つのステージでモデルを訓練します。各ステージのエポック数はtotal_epoch/4, total_epoch/2, total_epoch/4です。
-
事前学習済みモデル
ALL_ELEMENTS_LARGE_6を用いて、スクラッチで訓練したモデルと、事前学習済みモデルからファインチューニングしたモデルを比較します。 -
合計エポック数は200, 400, 800, 1600です。
Epochs
Training from scratch
Fine tuning from pretrained
200
large-scratch-1
large-pretrain-1
400
large-scratch-2
large-pretrain-2
800
large-scratch-3
large-pretrain-3
1600
large-scratch-4
large-pretrain-4
-
-
精度
-
小規模データセット
Epochs
Fine tuning from pretrained
Training from scratch
Energy
Forces
Stress
Energy
Forces
Stress
200
0.0021
0.0345
0.0006
0.0226
0.0665
0.0018
400
0.0013
0.0314
0.0005
0.0115
0.0603
0.0019
800
0.0010
0.0280
0.0005
0.0052
0.0516
0.0011
1600
0.0009
0.0270
0.0004
0.0049
0.0421
0.0008
-
大規模データセット
Epochs
Fine tuning from pretrained
Training from scratch
Energy
Forces
Stress
Energy
Forces
Stress
200
0.0009
0.0265
0.0005
0.0067
0.0398
0.0011
400
0.0007
0.0243
0.0005
0.0033
0.0357
0.0007
800
0.0007
0.0228
0.0004
0.0047
0.0292
0.0006
1600
0.0006
0.0215
0.0003
0.0010
0.0264
0.0005
-
-
弾性特性の誤差
-
小規模データセット
Epochs
Fine tuning from pretrained
Training from scratch
B (GPa)
G (GPa)
λ
B (GPa)
G (GPa)
λ
200
3.76
1.61
0.0003
6.2
12.47
0.0210
400
0.66
0.46
0.0016
2.88
18.22
0.0411
800
0.97
0.67
0.0023
10.12
23.35
0.0423
1600
1.08
0.53
0.0001
12.38
9.81
0.0092
-
大規模データセット
Epochs
Fine tuning from pretrained
Training from scratch
B (GPa)
G (GPa)
λ
B (GPa)
G (GPa)
λ
200
2.59
4.27
0.0065
9.15
13.55
0.0207
400
5.19
4.17
0.0038
3.6
10.39
0.025
800
5.09
4.21
0.004
0.71
7.06
0.0142
1600
4.1
0.32
0.0033
1.99
3.85
0.0062
-
-
分子動力学シミュレーションにおける密度の誤差 (g/cm3)
-
小規模データセット
Epochs
Fine tuning from pretrained
Training from scratch
300 K
500 K
1000 K
1500 K
2000 K
300 K
500 K
1000 K
1500 K
2000 K
200
0.01069
0.00942
0.00252
0.00171
0.0521
0.01249
0.01306
0.01655
0.02709
N/A
400
0.00934
0.01016
0.00198
0.00401
0.054
0.01294
0.02241
0.02529
0.03138
1.78746
800
0.00816
0.00969
0.00306
0.00609
0.00437
0.00341
0.00556
0.00119
0.00657
0.83045
1600
0.00721
0.00714
0.00206
0.006
0.01395
0.00643
0.00871
0.00292
0.01398
1.34568
-
大規模データセット
Epochs
Fine tuning from pretrained
Training from scratch
300 K
500 K
1000 K
1500 K
2000 K
300 K
500 K
1000 K
1500 K
2000 K
200
0.00619
0.00843
0.00036
0.00277
0.09592
0.01046
0.0134
0.00391
0.00517
N/A
400
0.00496
0.00706
0.00136
0.00165
0.43647
0.00441
0.00537
0.00171
0.00348
1.52342
800
0.00444
0.00526
0.00073
0.00046
0.42629
0.00781
0.00782
0.00251
0.00698
0.22416
1600
0.00471
0.00569
0.00054
0.00238
0.05718
0.00817
0.00682
0.00259
0.00678
N/A
-
ケース2: 有機分子#
-
対象物質:
-
ペンタンニトリル, C5H9N
-
SMILES:
CCCCC#N -
CID: 8061
-
-
データセットの準備
-
小規模データセット: 700構造
-
大規模データセット: 1524構造
-
-
LightPFPモデルの準備
Epochs
Training from scratch
Fine tuning from pretrained
80
small-scratch-1
small-pretrain-1
160
small-scratch-2
small-pretrain-2
320
small-scratch-3
small-pretrain-3
640
small-scratch-4
small-pretrain-4
-
エネルギー/力/応力の誤差
-
小規模データセット
Epochs
Fine tuning from pretrained
Training from scratch
Energy
Forces
Stress
Energy
Forces
Stress
80
0.00096
0.0819
0.00038
0.00149
0.1586
0.00071
160
0.00084
0.0650
0.00031
0.00115
0.1280
0.00065
320
0.00074
0.0614
0.00027
0.00089
0.0812
0.00037
640
0.00060
0.0582
0.00026
0.00064
0.0693
0.00030
-
大規模データセット
Epochs
Fine tuning from pretrained
Training from scratch
Energy
Forces
Stress
Energy
Forces
Stress
80
0.00097
0.0654
0.00032
0.00099
0.0905
0.00049
160
0.00077
0.0608
0.00029
0.00117
0.1153
0.00060
320
0.00071
0.0574
0.00027
0.00077
0.0718
0.00034
640
0.00061
0.0551
0.00026
0.00069
0.0734
0.00034
-
-
分子動力学シミュレーションにおける密度の誤差
-
小規模データセット
Epochs
Fine tuning from pretrained
Training from scratch
300 K
350 K
400 K
300 K
350 K
400 K
80
0.00708
0.00308
0.00094
N/A
N/A
N/A
160
0.01391
0.00707
0.00701
N/A
N/A
N/A
320
0.00199
0.00034
0.00068
0.07396
0.06922
0.06056
640
0.02317
0.0308
0.02752
0.01852
0.01206
0.009
-
大規模データセット
Epochs
Fine tuning from pretrained
Training from scratch
300 K
350 K
400 K
300 K
350 K
400 K
80
0.00125
0.01453
0.02061
0.01938
0.0381
0.0298
160
0.0029
0.00761
0.01417
0.05347
0.09456
0.74702
320
0.00027
0.0052
0.00657
0.0016
0.00471
0.00756
640
0.007
0.00215
0.0042
0.00473
0.01231
0.01098
-
ケース3: 固体/液体界面#
-
対象物質:
-
Pt (111) / ベンゼン界面
-
-
精度
Epochs
Fine tuning from pretrained
Training from scratch
Energy
Forces
Stress
Energy
Forces
Stress
80
0.0020
0.0924
0.0006
0.0053
0.1045
0.0013
200
0.0015
0.0744
0.0005
0.0017
0.0721
0.0006
-
界面上の原子分布
-
エポック数を80としてスクラッチでポテンシャルを訓練した場合、MDは失敗しました。
-
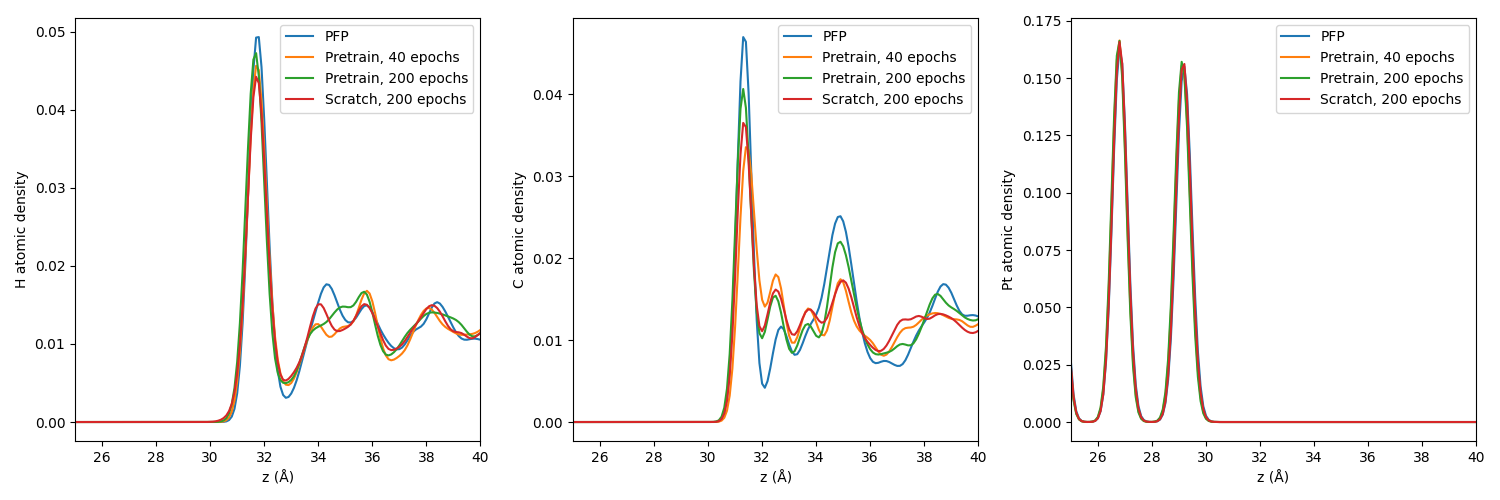
垂直方向に沿ったH、C、Pt原子の分布。#
付録3: ブックキーピングのベンチマーク#
以下のベンチマークでは、Exmaplesで提示したモデルと、水(H2O)用にトレーニングされた追加のモデルを使用しました。
選択した原子構造のスーパーセルのサイズを増やして、さまざまな温度(300K、400K、1000K)でMDシミュレーションを実行しました。
固体および液体構造の両方でブックキーピングがどのように機能するかを示すために、これらの温度を選択しました。
LARGEサイズの事前学習モデルを使用してトレーニングされたモデルを使用すると、MDシミュレーション時間を約25-30%削減できることが示されました。
またSMALLサイズの事前学習モデルを使用すると、約35-50%の削減が可能です。
ブックキーピング機能の誤用は、パフォーマンスの低下を引き起こす可能性があることに注意してください。
ケース1: Ni3Al#
このベンチマークでは、事前学習済みモデル ALL_ELEMENTS_LARGE_6 を用いてトレーニングされたモデルを使用しました。

|
Name |
Number of atoms |
Duration w/o bookkeeping |
Duration w/ bookkeeping |
Speedup |
|---|---|---|---|---|
|
AlNi3_333 |
108 |
27.63 |
17.46 |
37% |
|
AlNi3_666 |
864 |
26.22 |
17.63 |
33% |
|
AlNi3_999 |
2916 |
41.94 |
26.52 |
37% |
|
AlNi3_121212 |
6912 |
79.96 |
55.65 |
30% |
|
AlNi3_151515 |
13500 |
136.06 |
101.27 |
26% |
|
AlNi3_181818 |
23328 |
238.46 |
170.98 |
28% |
|
AlNi3_212121 |
37044 |
347.56 |
265.27 |
24% |
|
AlNi3_242424 |
55296 |
533.65 |
392.70 |
26% |
|
AlNi3_272727 |
78732 |
738.73 |
556.68 |
25% |
ALL_ELEMENTS_SMALL_6 を使用して、さらに大規模な構造を用いたMDによる推論のベンチマークを行い、ブックキーピングを使用した場合により顕著に処理が高速になることを確認しました。

|
Name |
Number of atoms |
Duration w/o bookkeeping |
Duration w/ bookkeeping |
Speedup |
|---|---|---|---|---|
|
AlNi3_small_333 |
108 |
16.45 |
10.38 |
37% |
|
AlNi3_small_666 |
864 |
18.87 |
10.47 |
45% |
|
AlNi3_small_999 |
2916 |
27.04 |
13.05 |
52% |
|
AlNi3_small_121212 |
6912 |
49.81 |
25.35 |
49% |
|
AlNi3_small_151515 |
13500 |
84.64 |
45.19 |
47% |
|
AlNi3_small_181818 |
23328 |
154.12 |
74.95 |
51% |
|
AlNi3_small_212121 |
37044 |
208.02 |
115.75 |
44% |
|
AlNi3_small_242424 |
55296 |
293.01 |
170.55 |
42% |
|
AlNi3_small_272727 |
78732 |
411.95 |
240.54 |
42% |
|
AlNi3_small_303030 |
108000 |
570.83 |
328.27 |
42% |
|
AlNi3_small_333333 |
143748 |
759.39 |
440.38 |
42% |
|
AlNi3_small_363636 |
186624 |
973.55 |
572.90 |
41% |
|
AlNi3_small_393939 |
237276 |
1220.75 |
734.60 |
40% |
|
AlNi3_small_424242 |
296352 |
1516.11 |
921.44 |
39% |
|
AlNi3_small_454545 |
364500 |
1867.19 |
1140.41 |
39% |
|
AlNi3_small_484848 |
442368 |
2278.22 |
OOM |
N/A |
ケース2: 液体の有機分子#
このベンチマークは、ALL_ELEMENTS_SMALL_6 と同様のパラメータを持つ ORGANIC 事前学習モデルを用いて訓練されたモデルを使用して、ペンタンニトリル分子に対して実行されました。

|
300K |
400K |
||||||
|---|---|---|---|---|---|---|---|
|
Name |
Number of atoms |
Duration w/o bookkeeping@300K |
Duration w/ bookkeeping@300K |
Speedup |
Duration w/o bookkeeping@400K |
Duration w/ bookkeeping@400K |
Speedup |
|
molecule_333 |
5670 |
51.66 |
31.87 |
38% |
52.70 |
36.20 |
31% |
|
molecule_666 |
45360 |
334.65 |
222.52 |
34% |
339.74 |
226.99 |
33% |
|
molecule_999 |
153090 |
1081.55 |
760.63 |
30% |
1095.14 |
780.10 |
29% |
ケース3: 液体アルミニウム#
初期構造: Al (mp-143) MD@1000K

|
Name |
Number of atoms |
Duration w/o bookkeeping |
Duration w/ bookkeeping |
Speedup |
|---|---|---|---|---|
|
Al_333 |
108 |
33.02 |
18.19 |
45% |
|
Al_666 |
864 |
32.44 |
18.66 |
42% |
|
Al_999 |
2916 |
42.69 |
22.81 |
47% |
|
Al_121212 |
6912 |
66.68 |
44.50 |
33% |
|
Al_151515 |
13500 |
105.84 |
80.24 |
24% |
|
Al_181818 |
23328 |
174.14 |
130.81 |
25% |
|
Al_212121 |
37044 |
268.79 |
200.96 |
25% |
|
Al_242424 |
55296 |
390.17 |
293.05 |
25% |
|
Al_272727 |
78732 |
557.97 |
414.31 |
26% |
|
Al_303030 |
108000 |
756.67 |
571.19 |
25% |
|
Al_333333 |
143748 |
997.33 |
762.56 |
24% |
|
Al_363636 |
186624 |
1283.69 |
OOM |
N/A |
ALL_ELEMENTS_SMALL_6 を使用して、さらに大規模な構造を用いたMDによる推論のベンチマークを行い、ブックキーピングを使用した場合により顕著に処理が高速になることを確認しました。

|
Name |
Number of atoms |
Duration w/o bookkeeping |
Duration w/ bookkeeping |
Speedup |
|---|---|---|---|---|
|
Al_small_333 |
108 |
16.0537281 |
10.44920731 |
35% |
|
Al_small_666 |
864 |
21.47774506 |
10.84698105 |
49% |
|
Al_small_999 |
2916 |
24.08777428 |
12.44081116 |
48% |
|
Al_small_121212 |
6912 |
38.2131424 |
21.20424843 |
45% |
|
Al_small_151515 |
13500 |
66.12276459 |
36.80934143 |
44% |
|
Al_small_181818 |
23328 |
102.7692413 |
59.63482285 |
42% |
|
Al_small_212121 |
37044 |
158.1944733 |
90.08835602 |
43% |
|
Al_small_242424 |
55296 |
223.6481476 |
132.2861176 |
41% |
|
Al_small_272727 |
78732 |
318.5072021 |
186.3789063 |
41% |
|
Al_small_303030 |
108000 |
432.7628784 |
254.4521179 |
41% |
|
Al_small_333333 |
143748 |
575.7253418 |
341.2708435 |
41% |
|
Al_small_363636 |
186624 |
730.7637939 |
442.0396118 |
40% |
|
Al_small_393939 |
237276 |
909.8272095 |
561.0055542 |
38% |
|
Al_small_424242 |
296352 |
1123.424438 |
702.6166992 |
37% |
|
Al_small_454545 |
364500 |
1373.670776 |
886.9639282 |
35% |
|
Al_small_484848 |
442368 |
1680.828003 |
1081.276367 |
36% |
|
Al_small_515151 |
530604 |
2007.58606 |
1303.386841 |
35% |
|
Al_small_545454 |
629856 |
2390.796631 |
OOM |
N/A |
ケース4: 水#
初期構造: H2O (mp-697111) MD@300K
このベンチマークは、事前学習済みモデル ALL_ELEMENTS_LARGE_6 を使用してトレーニングされたモデルを使用して実行されました。

|
Name |
Number of atoms |
Duration w/o bookkeeping |
Duration w/ bookkeeping |
Speedup |
|---|---|---|---|---|
|
water_333 |
324 |
31.34 |
21.06 |
33% |
|
water_666 |
2592 |
46.33 |
29.74 |
36% |
|
water_999 |
8748 |
108.50 |
79.68 |
27% |
|
water_121212 |
20736 |
225.95 |
172.85 |
24% |
|
water_151515 |
40500 |
454.82 |
328.56 |
28% |
|
water_181818 |
69984 |
753.66 |
563.49 |
25% |
|
water_212121 |
111132 |
1171.09 |
901.72 |
23% |
ALL_ELEMENTS_SMALL_6 を使用して、さらに大規模な構造を用いたMDによる推論のベンチマークを行い、ブックキーピングを使用した場合により顕著に処理が高速になることを確認しました。

|
Name |
Number of atoms |
Duration w/o bookkeeping |
Duration w/ bookkeeping |
Speedup |
|---|---|---|---|---|
|
water_small_333 |
324 |
19.5056591 |
12.61014271 |
35% |
|
water_small_666 |
2592 |
29.79653168 |
14.39700794 |
52% |
|
water_small_999 |
8748 |
67.94934082 |
35.29168701 |
48% |
|
water_small_121212 |
20736 |
149.3302765 |
76.3841629 |
49% |
|
water_small_151515 |
40500 |
262.9512024 |
143.1963501 |
46% |
|
water_small_181818 |
69984 |
430.9408569 |
245.7056427 |
43% |
|
water_small_212121 |
111132 |
666.0740967 |
395.3837891 |
41% |
|
water_small_242424 |
165888 |
967.9492188 |
586.9674072 |
39% |
|
water_small_272727 |
236196 |
1354.013794 |
850.3184814 |
37% |
|
water_small_303030 |
324000 |
1855.304688 |
1172.999634 |
37% |
付録4: 並列実行のベンチマーク#
この章では、並列実行のパフォーマンスに関するベンチマーク結果を示します。
ブックキーピングと並列実行ベンチマーク#
LightPFPのExample modelとして提供しているモデル examplesv1alni3s を使用して、複数のジョブをjoblibライブラリを用いて並列に実行した際のパフォーマンスを比較しました。
本章で使用したベンチマークのコードの概要は以下の通りです。
import ase
from ase.build import bulk
from light_pfp_client.estimator import Estimator
from light_pfp_client.ase_calculator import ASECalculator
from ase import units
from ase.md.langevin import Langevin
from joblib import Parallel, delayed
import time
def run_md(atoms: ase.Atoms, book_keeping: bool):
estimator = Estimator(model_id="examplesv1alni3s", book_keeping=book_keeping)
calculator = ASECalculator(estimator)
atoms.calc = calculator
dyn = Langevin(atoms, 5 * units.fs, temperature_K=300.0, friction=0.002)
dyn.run(20)
# Plot the retuned value varying n_atoms_per, n_jobs and book_keeping
# n_atoms_per defines the number of atoms in the system
# n_jobs defines the number of parallel jobs to run
def benchmark_parallel_md(n_atoms_per: int, n_job: int, book_keeping: bool):
atoms_list = [bulk("Al") * (n_atoms_per, n_atoms_per, n_atoms_per) for _ in range(n_job)]
start = time.time()
Parallel(n_jobs=n_job, backend="threading")(
delayed(run_md)(atoms, book_keeping) for atoms in atoms_list
)
end = time.time()
elapsed = end - start
return elapsed
まず一つ目のベンチマークでは、並列実行するジョブの数を1から10まで変化させ、全てのジョブが完了するまでにかかる時間を比較しました。
(なお、並列実行のセクションで述べたように現在LightPFPでは10個までの推論に必要な情報のみをサーバーに保存することができることに注意してください。)
また、各ジョブで使用する構造の原子数も変化させ、その影響を調査しました。
最初の図はブックキーピングを使用しない場合の結果を示し、次の図はブックキーピングを使用した場合の結果を示しています。
横軸がジョブで使用する構造中の原子数(100原子から200,000原子程度まで)、縦軸が全てのジョブの完了までに要する時間であり、異なるジョブの数の結果については色で区別しています。
なお、縦軸の縮尺は統一されています。
最初の画像がブックキーピングを使用しない場合の結果を示し、次の画像がブックキーピングを使用した場合の結果を示しています。


この図から、並列実行の数が10以下の場合には、ブックキーピングを使用することで常にパフォーマンスが向上している様子が見て取れます。
また、ブックキーピングを使用した場合も使用していない場合も、ジョブの数に対してほぼ線形に全てのジョブが完了するまでに要している時間が増加していることがわかります。
この結果から、並列実行するジョブの数が10以下であれば、ブックキーピングを使用することでパフォーマンスが向上することが期待できることがわかります。
次に同様のベンチマークを、ジョブの数を8から15まで変化させ、全てのジョブが完了するまでにかかる時間を比較しました。
縦軸、横軸ともに先ほどのベンチマークと同様であり、縦軸の縮尺も統一されています。


この図から、並列実行の数が10を超える場合、ブックキーピングを使用することでパフォーマンスが低下していることが見られます。
これはブックキーピングのセクションで述べたように、10以上のジョブを並列で実行すると、隣接情報がうまく再利用されないが隣接情報の再作成・削除のオーバーヘッドが発生し、パフォーマンスの低下が生じるためです。
また、ブックキーピングを使用しない場合には、10以上のジョブを並列実行してもパフォーマンスの劣化は見られないことも分かります。
これはブックキーピングを使用しない場合は、推論に必要なモデルなどの情報のロードや削除にかかるオーバーヘッドが比較的少ないからだと考えられます。
しかし、ブックキーピングを有効活用した方が各ジョブが高速に完了することが期待されるため、10個以上のジョブを実行する際は、10個以下のジョブを並列でブックキーピングで実行し、
それらが完了してから次の10個のジョブを実行するなどの方法で実行することが最もパフォーマンスが高いことが期待されます。
最後に、並列実行およびブックキーピングの計算可能な原子数に関する影響を調査しました。
このベンチマークでは、ジョブの数を1から15まで、そして原子数を500,000程度から1,000,000程度まで変化させ、各ジョブ数ごとにどのサイズの構造までシミュレーションできるのかについて計測しました。
横軸と縦軸の意味は先ほどのベンチマークと同様であり、ブックキーピングを有効にした際の結果が示されています。
グラフが途中で途切れているのは、メモリが不足して計算が中断されたことを示しています。
この図から、並列で実行されているジョブの数が増えると計算可能な原子数が減少することがわかります。
これはブックキーピングのセクションで述べたように、ブックキーピングを使用すると隣接情報の保存のためにメモリが占有され、推論に割り当て可能なメモリのサイズが小さくなるためです。
