応用物理学会春季学術講演会のWeb予稿集が公開され、いよいよ学会シーズンの到来を感じますね。予稿集の提出を終えて発表準備に追われている方や、公開された予稿を見て聴講計画を立てている方も多いのではないでしょうか。
私は昨年の第86回応用物理学会秋季学術講演会にて、「PFP descriptorsとShapley値を組み合わせた原子レベルでの予測の解釈」というテーマで発表を行いました。 ありがたいことに当日は多くの方にご聴講いただき、大変なご好評をいただきました。マテリアルズインフォマティクス(MI)分野において、「AIがなぜそう予測したのか」という「解釈性(Explainability)」への需要がいかに高いかを、肌で感じる機会となりました。
そこで今回は、学会シーズンの到来に合わせて、当時の発表内容をベースに記事を執筆しました。学会の短い時間では伝えきれなかった詳細な背景や前提知識も含め、丁寧に解説していきます。
1. PFP descriptorsとは
まず、機械学習の記述子として用いるPFP descriptorsについて説明します。PFP descriptorsは汎用機械学習ポテンシャルPFPの最終層の情報を出力する機能です[1]。各原子に対し、その周辺環境を表現する256次元のベクトルが割り当てられております。これら256個の数値の一つひとつに直感的な物理的意味はありませんが、PFPの計算精度を支える高度な情報を含んでいます。この情報を転用することで、材料の物性を高精度で予測できることが報告されています[2, 3]。
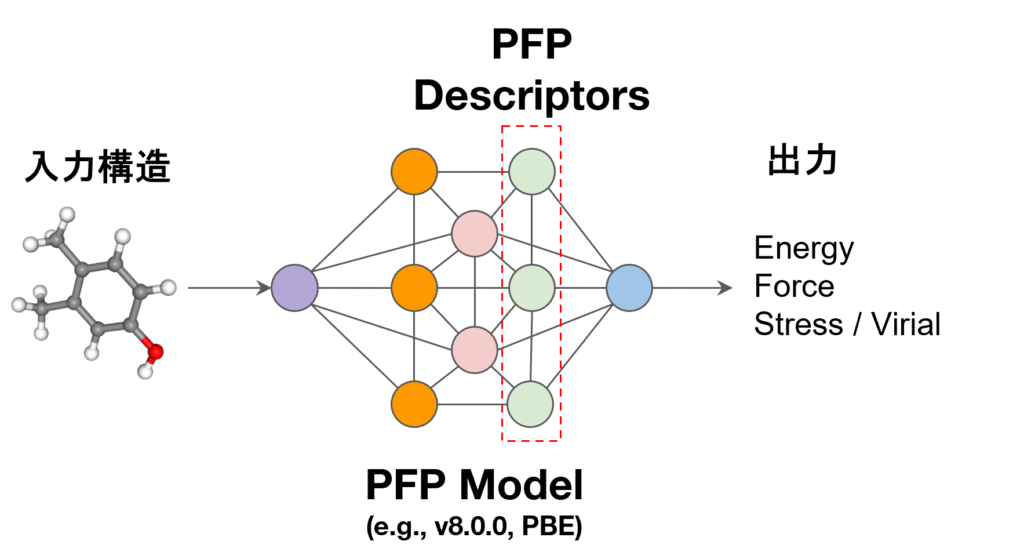
Figure 1. PFP descriptors
2. Shapley値とは
次に、機械学習モデルを解釈する際の核心となるShapley値について紹介します。Shapley値は、ゲーム理論で用いられる考え方で、チーム全体で得られた利得を、各プレイヤーの貢献度に応じて分配するための計算方法です。 中心的なアイデアは、”もしその人がチームに参加したら、全体の利益はどれくらい増えたか?”を、あらゆるパターンで考え、その平均値をそのプレイヤーの貢献度(取り分)とする、というものです。
2-1. 具体例
次の具体例を見ながら説明していきます。 A、B、Cの3人のプレイヤーがおり、参加する組み合わせによって得られる利得が Table 1 のように定義されているとします。このとき、3人全員が参加して得られた利得を、各メンバーにどのように分配すればよいでしょうか?
Table 1. プレイヤーと利得の関係
| 参加プレイヤー | 利得 |
| 誰も参加しない | 0 |
| A | 1 |
| B | 2 |
| C | 3 |
| A, B | 6 |
| A, C | 7 |
| B, C | 8 |
| A, B, C | 15 |
ここで、あるメンバーの貢献度を”そのプレイヤーがチームに加わったことで、利得がどれだけ増えたか”を基準に考えます。
しかし、増える利得の量は”既に誰がチームに入っているか”によって変わります。
- 誰もいない(利得: 0)ところにAが参加した場合(利得: 1):Aの貢献度は 1
- 既にBがいる(利得: 2)ところにAが参加した場合(利得: 6):Aの貢献度は 4
このように、既に入っているメンバーによって、増える利得の量は変わります。そのため、既に入っているメンバーの全パターンを考え、平均することで各メンバーの貢献度を定義します。
具体的な計算はTable2のようになります。例えば、A→B→Cと参加した場合を見てみましょう。
- 誰もいない(利得: 0)ところにAが参加した場合(利得: 1):Aの貢献度は1
- 既にAがいる(利得: 1)ところにBが参加した場合(利得: 6):Bの貢献度は5
- 既にA,Bがいる(利得: 6)ところにCが参加した場合(利得: 15):Cの貢献度は9
このように全パターンについて計算し、それらを平均した結果が、各メンバーのShapley値(Table2の最下行)です。計算結果からもわかるように、Shapley値には”各メンバーの貢献度の合計が、全メンバー参加時の総利得と一致する”という、分配において非常に都合の良い性質があります。
Table 2. 各プレイヤーの貢献度
| 参加順 | Aの貢献度 | Bの貢献度 | Cの貢献度 |
| A → B → C | 1 | 5 | 9 |
| A → C → B | 1 | 8 | 6 |
| B → A → C | 4 | 2 | 9 |
| B → C → A | 7 | 2 | 6 |
| C → A → B | 4 | 8 | 3 |
| C → B → A | 7 | 5 | 3 |
| 平均 | 4 | 5 | 6 |
2-2. 一般化と近似手法
上記操作を一般化すると以下の式になります。
Φiはプレイヤーiの貢献度、Nはプレイヤーの全体集合、Sは部分集合、|S|は部分集合に入っているプレイヤー数、|N|は全プレイヤー数、νは参加したプレイヤーから利得を計算するための価値関数です。Shapley値は各プレイヤーの貢献度の合計が利得と一致するという良い性質を有しますが、全プレイヤー数がnのとき、計算オーダーはO(2n)と非常に高いです。そこでShapley値を以下のShapley Kernelで重み付けた線形回帰で近似する手法が提案されました[4]。
z’は各プレイヤーが参加しているかを表すone hot vector、Mは全プレイヤー数です。Shapley Kernelで近似できることの証明は論文をご参照ください。(今回の例をShapley Kernelで計算するpythonコードは付録に掲載しております。ご活用ください。)
3. PFP descriptorsとShapley値を組み合わせた解釈
では、これらを組み合わせて、どのように材料特性を解釈するのでしょうか。そして、なぜPFP descriptorsを使うのでしょうか。それは、PFP descriptorsには、通常の材料記述子にはない大きなメリットがあるからです
通常の機械学習モデルでは、特定の特徴量を考慮したくない場合にもその特徴量を無視して、入力しないことはできません。
しかし、PFP descriptorsは”原子ごとの特徴量”です。各原子の特徴量を合計などの演算によって集約(readout)し、分子全体の記述子に変換して利用できます。そのため、ある原子の特徴量を無視(mask)しても、readout後のベクトルの次元数は変わらず、そのままモデルに入力して予測値を計算できます 。
これにより、”ある原子が存在しないときの予測値”を擬似的に作り出し、原子ごとのShapley値を計算することが可能になります。つまり、”どの原子が予測値にどれくらい寄与したか”を定量的に示せるのです 。
PFP descriptorsは事前に大量のデータを学習させたモデルの潜在変数であるため、材料特性を高精度に予測可能な機械学習モデルを構築することができます。機械学習モデルの予測を解釈する際、予測精度が低いモデルを解釈しても妥当な結果は得ることができません。そのため、PFP descriptorsとShapley値を組み合わせることで、化学的に妥当な解釈を得やすくなると考えられます。
解析事例:3,4-ジメチルフェノールの水溶解度
実際に、有機分子の水溶解度予測モデルを構築し、3,4-ジメチルフェノールの水溶解度予測を解釈した結果をFigure2に示します。
赤が正に寄与、青が負に寄与、色の濃さが寄与の大きさを表しています。メチル基やベンゼン環が青く、水酸基が赤くなっていることから、既知の化学的知見と整合することを確認しております。Shapley値を計算する際に原子ごとではなく、官能基ごとにmaskすることで、官能基レベルでの解釈を行うこともできます。
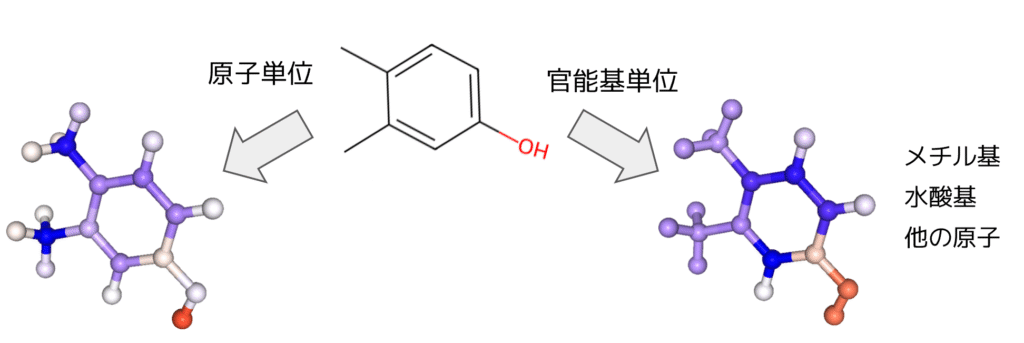
Figure 2. 3,4-ジメチルフェノールの水溶解度予測に対する解釈
この手法のExampleコードはMatlantis環境で公開しておりますので、ぜひお試しください。
補足:shapパッケージの手法とはなにが違うのか?
shapパッケージ [5]では、特徴量が存在しない状態を周辺化によって近似しますが、これには計算コストと近似誤差の問題があります。PFP descriptorsを用いた今回の手法では、各原子を直接maskできるため、周辺化が不要で、計算コストも誤差も抑えられるという利点があります 。
4. 今年の応用物理学会 春季学術講演会について
ここまで私の昨年の発表内容について紹介してきました。今年の応用物理学会 春季学術講演会におきましても、弊社より以下の4件の学術発表を行います。
今回の発表は、相図、電池材料、半導体材料、酵素反応と、それぞれ異なるセッションに跨っております。汎用機械学習力場が、物理、材料からバイオまでの幅広いテーマに対して適用可能であることを示す事例としてご覧いただければ幸いです。
【弊社発表一覧】
汎用機械学習ポテンシャルを使用した三元系温度相図シミュレーション
〇小鷹 浩毅(Matlantis株式会社)
汎用機械学習力場を用いたLiイオン電池正極材料の構造安定性および不可逆変化の解析
〇松本 皓太、平井 貴裕(Matlantis株式会社)
汎用機械学習力場を用いたALD precursorの吸着自由エネルギー計算に基づく蒸気圧予測モデルの検討
〇浅野 裕介(Matlantis株式会社)
〇山内 仁喬(Matlantis株式会社)
また、今年は弊社代表の岡野原が一般公開のセクションで講演いたします。
〇岡野原 大輔(Preferred Networks / Matlantis)
当日、会場で皆様と議論させていただけることを楽しみにしております!
付録:PythonによるShapley Kernelの計算例
本文中で紹介した、Shapley Kernelを用いてプレイヤーの貢献度を計算するPythonコードです。こちらを実行いただくことで、Shapley KernelがShapley値を近似できることを確認できます。
import itertools
import math
import numpy as np
coalition_to_value = {
(0, 0, 0): 0,
(1, 0, 0): 1, # A
(0, 1, 0): 2, # B
(0, 0, 1): 3, # C
(1, 1, 0): 6, # A, B
(1, 0, 1): 7, # A, C
(0, 1, 1): 8, # B, C
(1, 1, 1): 15, # A, B, C
}
M = 3
coalitions_binary = list(itertools.product([0, 1], repeat=M))
X = np.array(coalitions_binary)
y = np.array([coalition_to_value[c] for c in coalitions_binary])
def shapley_kernel_weight(M, s):
if s == 0 or s == M:
return 1e9
else:
combinations_term = math.comb(M, s)
denominator = combinations_term * s * (M - s)
kernel_weight = (M - 1) / denominator
return kernel_weight
kernel_weights = np.array([shapley_kernel_weight(M, np.sum(c)) for c in coalitions_binary])
X_matrix = np.hstack((np.ones((X.shape[0], 1)), X))
sqrt_weights = np.sqrt(kernel_weights)
X_weighted = X_matrix * sqrt_weights[:, np.newaxis]
y_weighted = y * sqrt_weights
coeffs, _, _, _ = np.linalg.lstsq(X_weighted, y_weighted, rcond=None)
shapley_values = coeffs[1:]
print(f"{shapley_values=}")References
[1] PFP Descriptors, (2026年1月30日閲覧)
[2] Z. Mao et. al., npj Comput. Mater. 10, 265 (2024).
[3] The Power of PFP Descriptors: Enhancing Prediction Tasks with Pre-trained Neural Network Potentials,(2026年1月27日閲覧)
[4] S. M. Lundberg, S. I. Lee., Adv. Neural Inf. Process. Syst. 30 (2017).
[5] https://github.com/shap/shap (2026年1月30日閲覧)
-




 URLを
URLを
コピーしました
新着記事
NEW
京大・福井謙一記念研究センターで学ぶ、研究を加速するAI材料シミュレーション──ENEOSと共に「最高のCO2吸着剤」設計に挑む

NEW
ゼロから書くSMILES記法

解説記事 計算化学

名古屋大学×Matlantis「最先端理工学実験」レポート AIシミュレーションが実験系学生の探究心に火をつけた4日間の集中講義
インタビュー 計算化学

機械学習ポテンシャル入門: 材料開発を加速するシミュレーション技術

機械学習力場 解説記事
東大SPRING GX講義で学ぶ、研究を加速するAI材料シミュレーションMatlantis──ENEOSとともに博士課程学生がAIによる分子設計シミュレーションを体験
インタビュー
